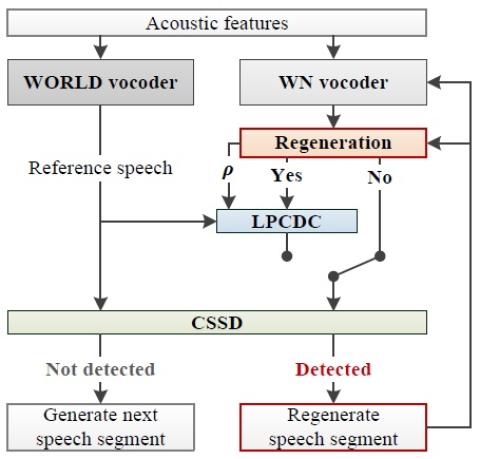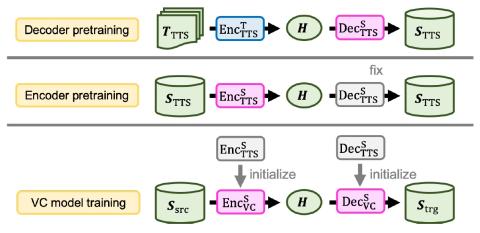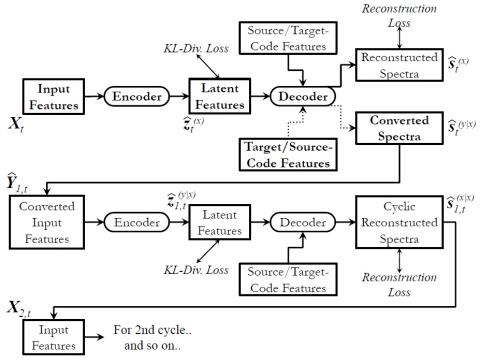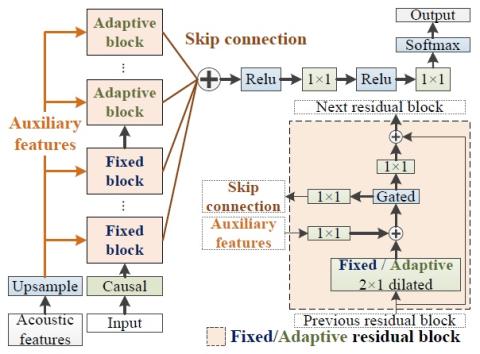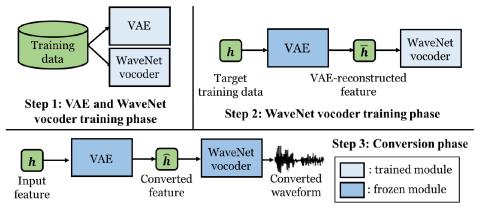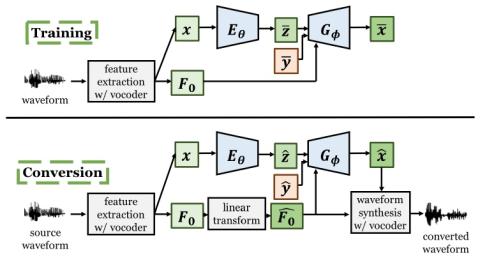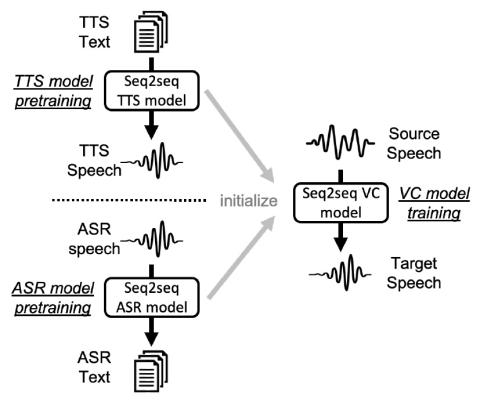
Pretraining Techniques for Sequence-to-Sequence Voice Conversion
Sequence-to-sequence (seq2seq) voice conversion (VC) models are attractive owing to their ability to convert prosody. Nonetheless, without sufficient data, seq2seq VC models can suffer from unstable training and mispronunciation problems in the converted speech, thus far from practical. To tackle these shortcomings, we propose to transfer knowledge from other speech processing tasks where large-scale corpora are easily available, typically text-to-speech (TTS) and automatic speech recognition (ASR). We argue that VC models initialized with such pretrained ASR or TTS model parameters can genera...