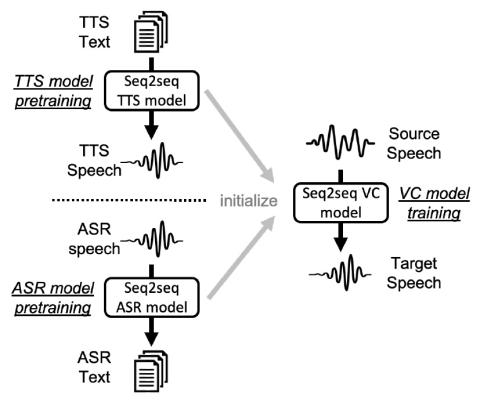
Sequence-to-sequence (seq2seq) voice conversion (VC) models are attractive owing to their ability to convert prosody. Nonetheless, without sufficient data, seq2seq VC models can suffer from unstable training and mispronunciation problems in the converted speech, thus far from practical. To tackle these shortcomings, we propose to transfer knowledge from other speech processing tasks where large-scale corpora are easily available, typically text-to-speech (TTS) and automatic speech recognition (ASR). We argue that VC models initialized with such pretrained ASR or TTS model parameters can generate effective hidden representations for high-fidelity, highly intelligible converted speech. We apply such techniques to recurrent neural network (RNN)-based and Transformer based models, and through systematical experiments, we demonstrate the effectiveness of the pretraining scheme and the superiority of Transformer based models over RNN-based models in terms of intelligibility, naturalness, and similarity.
Conclusions
In this work, we evaluated the pretraining techniques for addressing the problem of data efficiency in seq2seq VC. Specifically, a unified, two-stage training strategy that first pretrains the decoder and the encoder subsequently followed by initializing the VC model with the pretrained model parameters was proposed. ASR and TTS were chosen as source tasks to transfer knowledge from, and the RNN and VTN architectures were implemented. Through objective and subjective evaluations, it was shown that the TTS pretraining strategy can greatly improve the performance in terms of speech intelligibility and quality when applied to both RNNs and VTNs, and the performance could stay without significant degradation even with limited training data. As for ASR pretraining, the robustness was not so good with the reduction of training data size. Also, VTNs performed inferior to RNNs without pretraining but superior with TTS pretraining. The visualization experiment suggested that the TTS pretraining could learn a linguistic-information-rich hidden representation space while the ASR pretraining lacks such ability, which lets us imagine what an ideal hidden representation space would be like.
In the future, we plan to extend our pretraining technique to more flexible training conditions, such as many-to-many or nonparallel training.