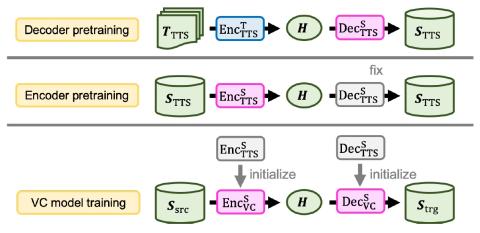
We introduce a novel sequence-to-sequence (seq2seq) voice conversion (VC) model based on the Transformer architecture with text-to-speech (TTS) pretraining. Seq2seq VC models are attractive owing to their ability to convert prosody. While seq2seq models based on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been successfully applied to VC, the use of the Transformer network, which has shown promising results in various speech processing tasks, has not yet been investigated. Nonetheless, their data-hungry property and the mispronunciation of converted speech make seq2seq models far from practical. To this end, we propose a simple yet effective pretraining technique to transfer knowledge from learned TTS models, which benefit from large-scale, easily accessible TTS corpora. VC models initialized with such pretrained model parameters are able to generate effective hidden representations for high-fidelity, highly intelligible converted speech. Experimental results show that such a pretraining scheme can facilitate data-efficient training and outperform an RNN-based seq2seq VC model in terms of intelligibility, naturalness, and similarity.
Conclusion
In this work, we successfully applied the Transformer structure to seq2seq VC. Also, to address the problems of data efficiency and mispronunciation in seq2seq VC, we proposed the transfer of knowledge from easily accessible, large-scale TTS corpora by initializing the VC models with pretrained TTS models. A two-stage training strategy that pretrains the decoder and the encoder subsequently ensures that fine-grained intermediate representations are generated and fully utilized. Objective and subjective evaluations showed that our pretraining scheme can greatly improve speech intelligibility, and it significantly outperformed an RNN-based seq2seq VC baseline. Even with limited training data, our system can be successfully trained without significant performance degradation. In the future, we plan to more systematically examine the effectiveness of the Transformer architecture compared with RNN-based models. Extension of our pretraining methods to more flexible training conditions, such as nonparallel training, is also an important future task.