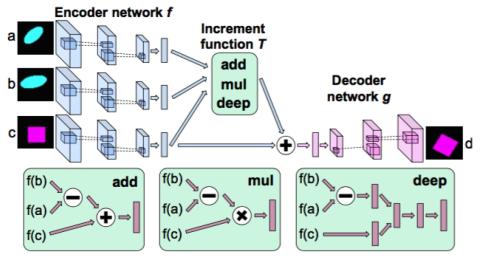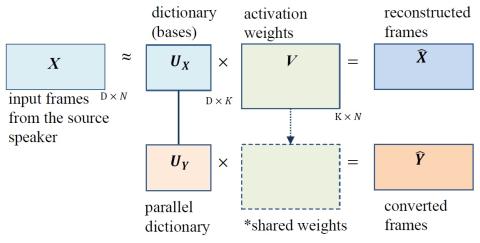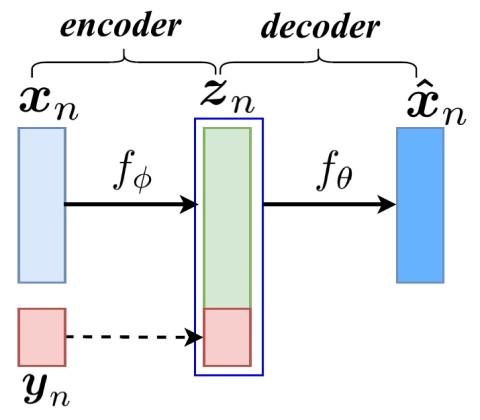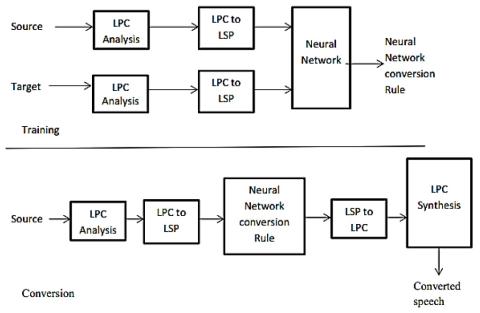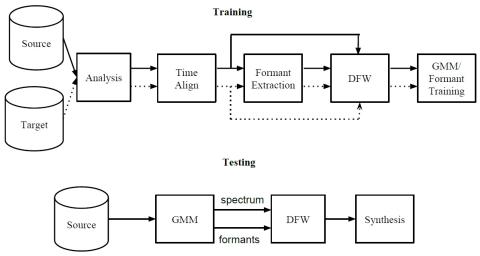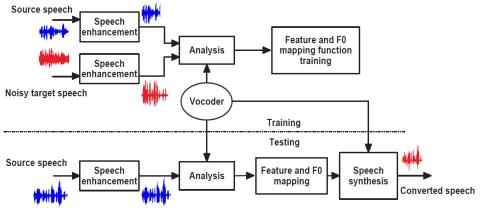
Robustness of Voice Conversion Techniques Under Mismatched Conditions
Most of the existing studies on voice conversion (VC) are conducted in acoustically matched conditions between source and target signal. However, the robustness of VC methods in presence of mismatch remains unknown. In this paper, we report a comparative analysis of different VC techniques under mismatched conditions. The extensive experiments with five different VC techniques on CMU ARCTIC corpus suggest that performance of VC methods substantially degrades in noisy conditions. We have found that bilinear frequency warping with amplitude scaling (BLFWAS) outperforms other methods in most of t...