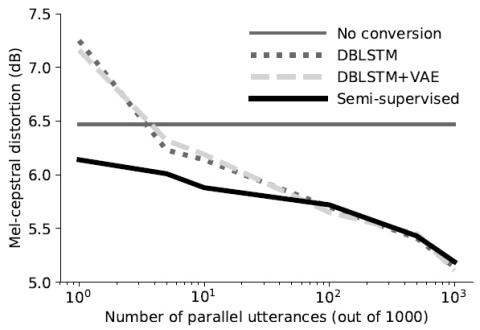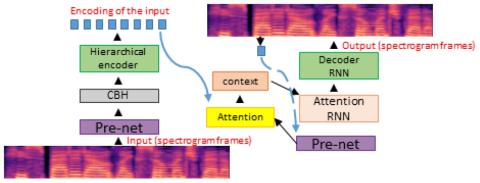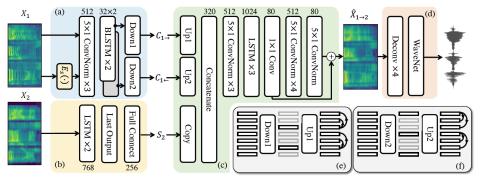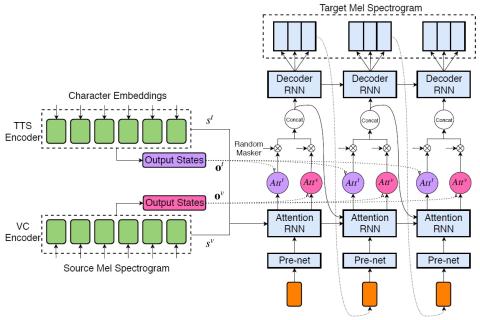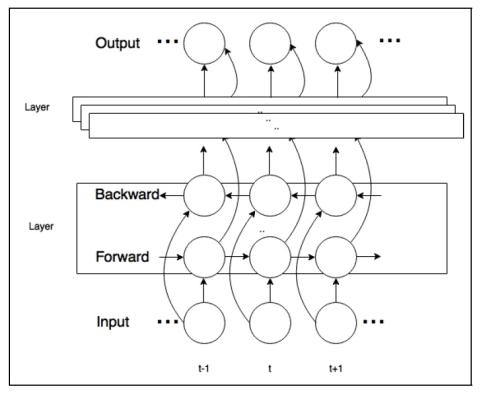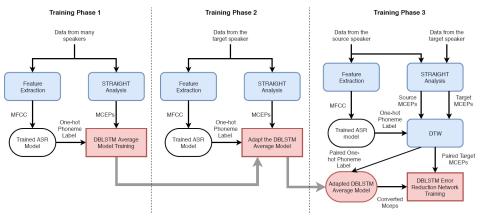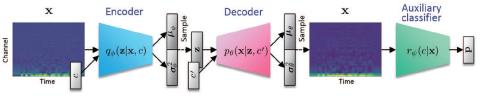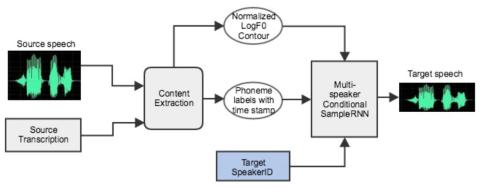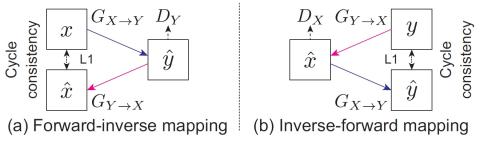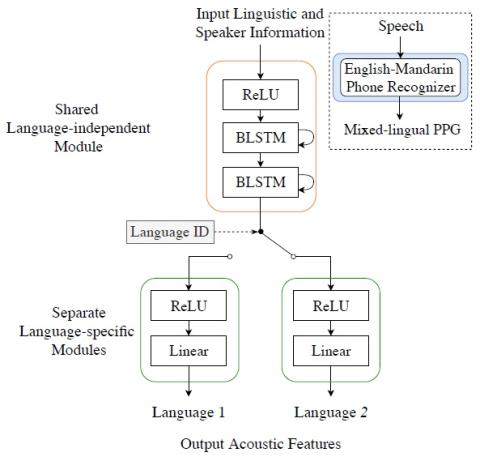
A Modularized Neural Network with Language-Specific Output Layers for Cross-lingual Voice Conversion
This paper presents a cross-lingual voice conversion framework that adopts a modularized neural network. The modularized neural network has a common input structure that is shared for both languages, and two separate output modules, one for each language. The idea is motivated by the fact that phonetic systems of languages are similar because humans share a common vocal production system, but acoustic renderings, such as prosody and phonotactic, vary a lot from language to language. The modularized neural network is trained to map Phonetic PosteriorGram (PPG) to acoustic features for multiple ...