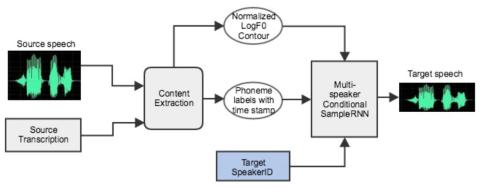
Here we present a novel approach to conditioning the SampleRNN generative model for voice conversion (VC). Conventional methods for VC modify the perceived speaker identity by converting between source and target acoustic features. Our approach focuses on preserving voice content and depends on the generative network to learn voice style. We first train a multi-speaker SampleRNN model conditioned on linguistic features, pitch contour, and speaker identity using a multi-speaker speech corpus. Voice-converted speech is generated using linguistic features and pitch contour extracted from the source speaker, and the target speaker identity. We demonstrate that our system is capable of many-to-many voice conversion without requiring parallel data, enabling broad applications. Subjective evaluation demonstrates that our approach outperforms conventional VC methods.
Conclusions
In this paper, we proposed a text-dependent VC method based on the conditional SampleRNN speech generative model. The advantage of the proposed method is that it does not require a parallel dataset and it does not have restrictions on source speakers. The experimental results demonstrate that the proposed method has a significant improvement on speech naturalness over the baseline system with much higher conversion accuracy on speaker identity. In future work, we plan to further improve speech quality and develop an end-to-end text-independent voice conversion method.