Singing voice conversion with non-parallel data
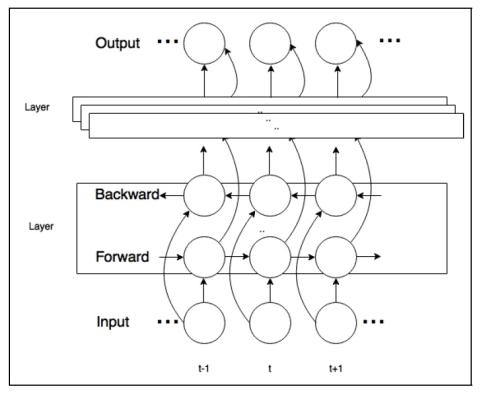
Singing voice conversion is a task to convert a song sang by a source singer to the voice of a target singer. In this paper, we propose using a parallel data free, many-to-one voice conversion technique on singing voices. A phonetic posterior feature is first generated by decoding singing voices through a robust Automatic Speech Recognition Engine (ASR). Then, a trained Recurrent Neural Network (RNN) with a Deep Bidirectional Long Short Term Memory (DBLSTM) structure is used to model the mapping from person-independent content to the acoustic features of the target person. F0 and aperiodic are...