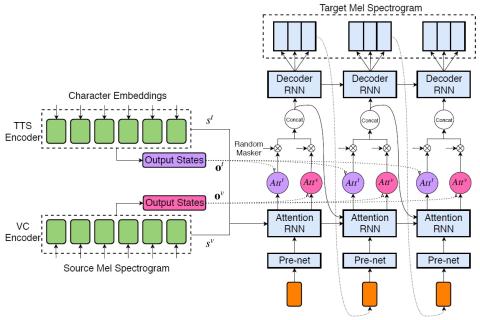
We investigated the training of a shared model for both text-to-speech (TTS) and voice conversion (VC) tasks. We propose using an extended model architecture of Tacotron, that is a multi-source sequence-to-sequence model with a dual attention mechanism as the shared model for both the TTS and VC tasks. This model can accomplish these two different tasks respectively according to the type of input. An end-to-end speech synthesis task is conducted when the model is given text as the input while a sequence-to-sequence voice conversion task is conducted when it is given the speech of a source speaker as the input. Waveform signals are generated by using WaveNet, which is conditioned by using a predicted mel-spectrogram. We propose jointly training a shared model as a decoder for a target speaker that supports multiple sources. Listening experiments show that our proposed multi-source encoder-decoder model can efficiently achieve both the TTS and VC tasks.
Conclusion and Future Work
In this paper, we proposed a joint model for both the TTS and VC tasks. The architecture of our model is based on Tacotron. Given text characters as input, the model conducts end-to-end speech synthesis. Given the spectrogram of a source speaker, the model conducts sequence-to-sequence voice conversion. The experimental results showed that our proposed model achieved both TTS and VC tasks and improved the performance of VC compared with the stand-alone model. Our future work will be to investigate a better method for the maskers of the input encoders and a more appropriate training algorithm.