Hierarchical Sequence to Sequence Voice Conversion with Limited Data
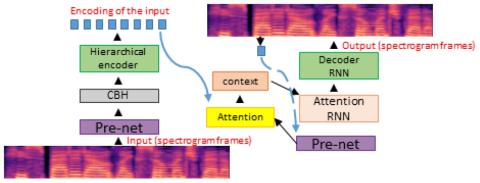
We present a voice conversion solution using recurrent sequence to sequence modeling for DNNs. Our solution takes advantage of recent advances in attention based modeling in the fields of Neural Machine Translation (NMT), Text-to-Speech (TTS) and Automatic Speech Recognition (ASR). The problem consists of converting between voices in a parallel setting when audio pairs are available. Our seq2seq architecture makes use of a hierarchical encoder to summarize input audio frames. On the decoder side, we use an attention based architecture used in recent TTS works. Since there is a dearth of large ...