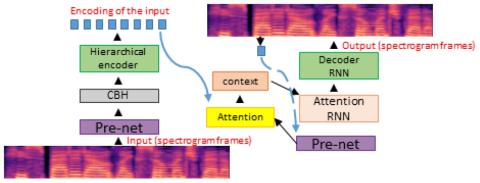
We present a voice conversion solution using recurrent sequence to sequence modeling for DNNs. Our solution takes advantage of recent advances in attention based modeling in the fields of Neural Machine Translation (NMT), Text-to-Speech (TTS) and Automatic Speech Recognition (ASR). The problem consists of converting between voices in a parallel setting when audio pairs are available. Our seq2seq architecture makes use of a hierarchical encoder to summarize input audio frames. On the decoder side, we use an attention based architecture used in recent TTS works. Since there is a dearth of large multi-speaker voice conversion databases needed for training DNNs, we resort to training the network with a large single speaker dataset as an autoencoder. This is then adapted for the smaller multi-speaker voice conversion datasets available for voice conversion. In contrast with other voice conversion works that use F0, duration and linguistic features, our system uses mel-spectrograms as the audio representation. Output mel frames are converted back to audio using a WaveNet vocoder.
Conclusions
In this work, we demonstrated a way to overcome data limitations (an all too common malady in the speech world) with a trick to extract linguistic features by pretraining with a large corpus so that it learns to reconstruct the input voice. These features serve as a useful starting point for transfer learning in the limited data corpus. The architecture proposed is slightly elaborate, in that it resorts to hierarchically reducing the number of timesteps on the encoder side. The basis for this proposal was in keeping with the fact that the content embedded in the input waveforms - viewed as words or phoneme like entities - is much smaller than the size of the waveforms (5 words vs 100 audio frames, 10 phonemes vs 100 audio frames, etc.). With this intuition, the hierarchical reduction in timesteps is viewed as a mechanism to extract phoneme like entities by compressing the content in the input mel-spectrogram. Our task is in a sense, to extract a style independent representation on the encoder side. The decoder then learns to inject the target speaker’s content using exactly the same type of architecture as in the Tacotron works. The output spectrograms are converted back to audio using a WaveNet vocoder, yielding plausible conversions, demonstrating that our approach is indeed legitimate.
The system is sensitive to hyperparameters. We noticed the capacity of the CBHG network is particularly important, and adding dropout at various places helps in generalizing to the small dataset. However, dropout also leads to ’blurriness’. Cleaning up the output is probably necessary with a postnet, which we have not implemented.
We hope to release code and samples to allow for experimentation.