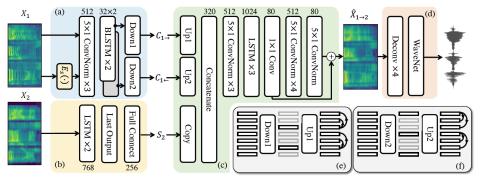
Non-parallel many-to-many voice conversion, as well as zero-shot voice conversion, remain underexplored areas. Deep style transfer algorithms, such as generative adversarial networks (GAN) and conditional variational autoencoder (CVAE), are being applied as new solutions in this field. However, GAN training is sophisticated and difficult, and there is no strong evidence that its generated speech is of good perceptual quality. On the other hand, CVAE training is simple but does not come with the distribution-matching property of a GAN. In this paper, we propose a new style transfer scheme that involves only an autoencoder with a carefully designed bottleneck. We formally show that this scheme can achieve distributionmatching style transfer by training only on a selfreconstruction loss. Based on this scheme, we proposed AUTOVC, which achieves state-of-theart results in many-to-many voice conversion with non-parallel data, and which is the first to perform zero-shot voice conversion.
Conclusion
In this paper, we have proposed AUTOVC, a non-parallel voice conversion algorithm that significantly outperforms the existing state-of-the-art, and that is the first to perform zero-shot conversions. In sharp contrast to its performance advantage is its simple autoencoder structure that trains only on self-reconstruction, and a bottleneck tuning to balance between reconstruction quality and speaker disentanglement. In an era of building increasingly sophisticated algorithms for style transfer, our theoretical justification and the success of AUTOVC suggest that it is time to return to simplicity, because sometimes an autoencoder with a careful bottleneck design is all you need to make a difference.