Voice Conversion Using Sequence-to-Sequence Learning of Context Posterior Probabilities
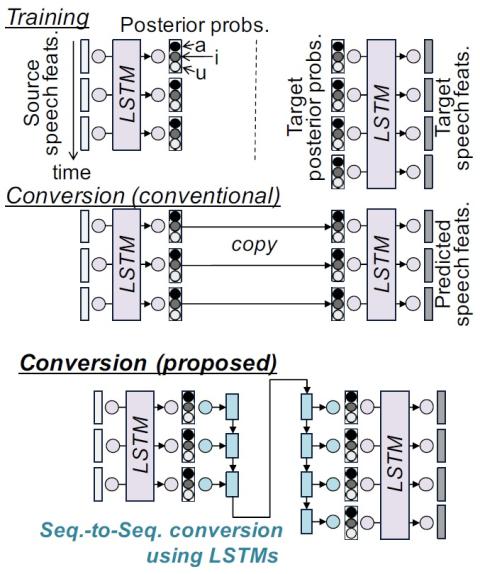
Voice conversion (VC) using sequence-to-sequence learning of context posterior probabilities is proposed. Conventional VC using shared context posterior probabilities predicts target speech parameters from the context posterior probabilities estimated from the source speech parameters. Although conventional VC can be built from non-parallel data, it is difficult to convert speaker individuality such as phonetic property and speaking rate contained in the posterior probabilities because the source posterior probabilities are directly used for predicting target speech parameters. In this work, w...