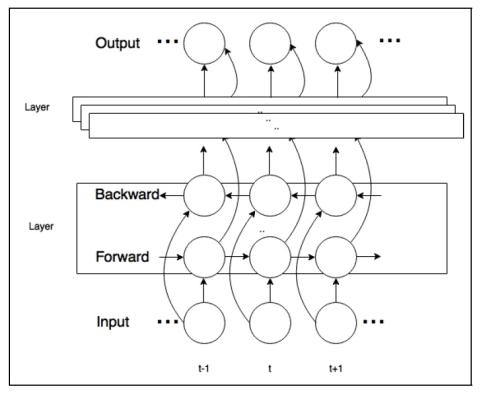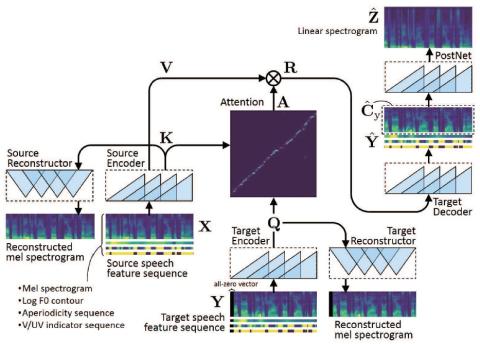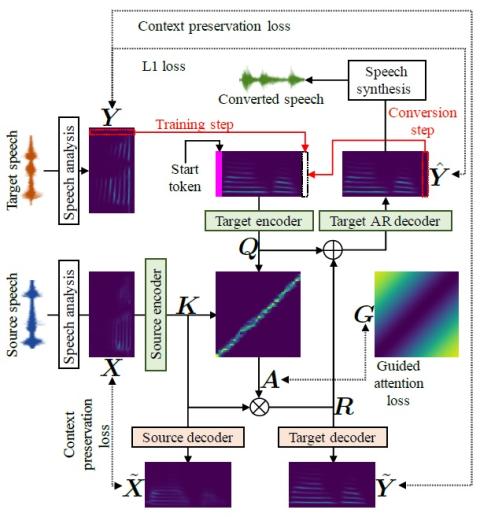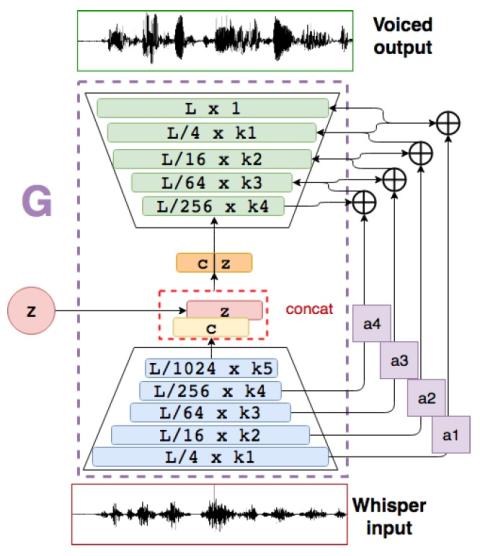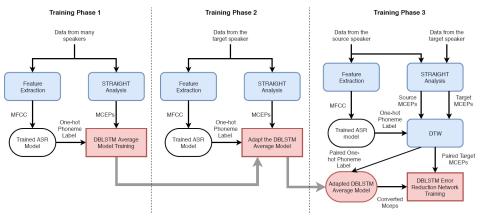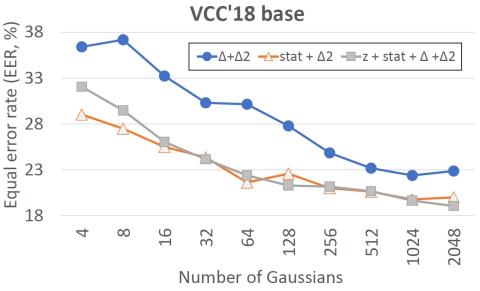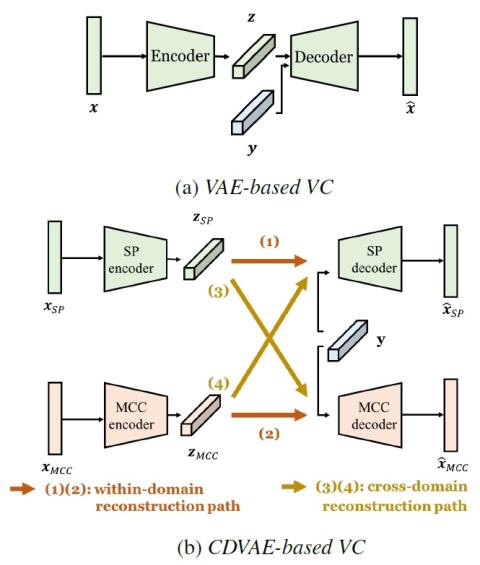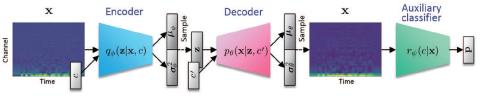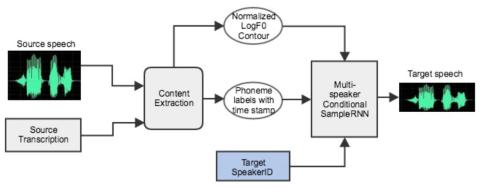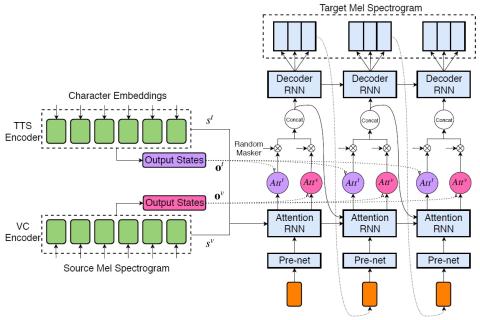
Совместная обучающая платформа для преобразования текста в речь и преобразования голоса с использованием Tacotron и WaveNet с несколькими источниками
Мы исследовали процесс обучения общей модели как для задач преобразования текста в речь, так и для задач преобразования голоса. Мы предлагаем использовать архитектуру расширенной модели Tacotron, которая представляет собой модель последовательного преобразования из нескольких источников с механизмом двойного внимания, в качестве общей модели как для задач преобразования текста в речь, так и для задач преобразования голоса. Эта модель может выполнять эти две различные задачи соответственно в зависимости от типа входных данных. Задача сквозного синтеза речи выполняется, когда модели в качестве в...