Преобразование голоса направлено на преобразование характеристик говорящего без изменения содержания. Из-за ограниченности обучающих данных и несовершенства моделирования трудно добиться правдоподобной имитации говорящего без внесения артефактов обработки; поэтому оценка эффективности преобразования голоса обычно включает в себя как сходство говорящего, так и оценку качества с помощью человека. Поскольку это трудоемкий, дорогостоящий и невоспроизводимый процесс, он затрудняет быстрое создание прототипов новой технологии преобразования голоса. Мы рассматриваем оценку искажений, используя альтернативный, объективный подход, основанный на результатах предыдущей работы по средствам противодействия подделке (CMs) для автоматической проверки говорящего. Таким образом, CMS используются для отклонения поддельных входных данных, таких как воспроизведенная, синтетическая или преобразованная речь, но их потенциал для автоматической оценки искажений речи остается неизвестным. Данное исследование призвано восполнить этот пробел. В дополнение к субъективным результатам конкурса Voice Conversion Challenge 2018 (VCC'18) мы настраиваем стандартный кепстральный коэффициент CM с постоянной величиной Q для количественной оценки степени искажений при обработке. Равная частота ошибок (EER) CM, индекса смешиваемости образцов преобразования голоса с реальной человеческой речью, служит нашим показателем артефакта. Из 18 записей VCC выделены две группы: низкокачественные с обнаруживаемыми артефактами (низкие EER) и более качественные с меньшим количеством артефактов. Однако ни одна из систем VCC'18 не идеальна: все EER составляют < 30 % (идеальным значением было бы 50 %). Наши предварительные выводы свидетельствуют о потенциале CMs за пределами их первоначального применения в качестве дополнительного инструмента оптимизации и сравнительного анализа для улучшения технологии преобразования голоса.
Вывод
Мы предложили использовать средства противодействия спуфингу для объективной оценки искажений преобразованных голосов в качестве дополнения к результатам конкурса VCC’18. Наш подход не содержит ссылок и не зависит от текста в том смысле, что он не требует доступа ни к исходному сигналу диктора, ни к каким-либо текстовым расшифровкам. Он присваивает единый номер EER пакету преобразованных речевых высказываний из одной системы преобразования голоса и, следовательно, может использоваться для сравнения различных систем преобразования голоса с точки зрения их артефактов.
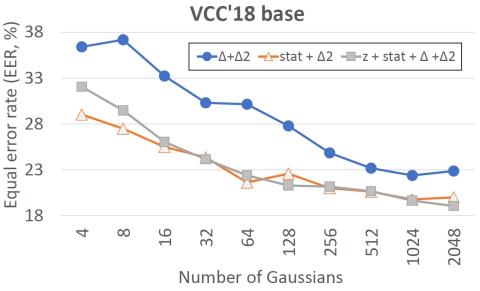
Хотя было обнаружено, что протестированные меры противодействия, использующие интерфейс CQCC и серверную часть GMM, чувствительны к выбору параметров модели и акустических характеристик, наши результаты указывают на явный потенциал оценки мер противодействия подделке как удобного и дополнительного инструмента для автоматической оценки количества слышимых и неслышимых речевых артефактов.
Полученные результаты находятся в разумном согласии с типами методов генерации сигналов, используемых в системах преобразования голоса. Наши результаты показывают, что методы фильтрации сигналов, SuperVP и Гриффина-Лима имеют относительно меньше искажений. Поскольку они не включены в текущие наборы данных ASVspoof, мы утверждаем, что также важно создавать новые материалы о спуфинге, основанные на этих методах, и обучать более надежным мерам противодействия спуфингу на практике.
Мы также обнаружили, что убедительные с точки зрения восприятия образцы преобразования голоса на основе Wavenet в VCC’18 содержат заметные артефакты. Это означает, что лучшие на данный момент образцы преобразования голоса могут обмануть человеческий слух, но не обязательно системы CM. Пока не существует системы, которая могла бы идеально одурачить как людей, так и компьютерные системы.
Хотя наше исследование служит подтверждением концепции, мы предвидим несколько возможных направлений в будущем. Во-первых, было бы интересно сравнить производительность со стандартными объективными показателями артефактов, используемыми при оценке речевых кодеков и методов улучшения речи, а также с другими интерфейсами для противодействия спуфингу, помимо CQCCs. Некоторые альтернативные функции могут обеспечить более сильную корреляцию с оценками MOS. Во-вторых, учитывая очевидную проблему, связанную с отбором и обогащением обучающих данных новейшими методами преобразования голоса, возможно, было бы уместно рассмотреть подходы с одним классом, которые требуют только обучения человеческой речи. Даже если такие подходы имели лишь умеренный успех в борьбе со спуфингом, было бы интересно вернуться к ним в контексте оценки артефактов.