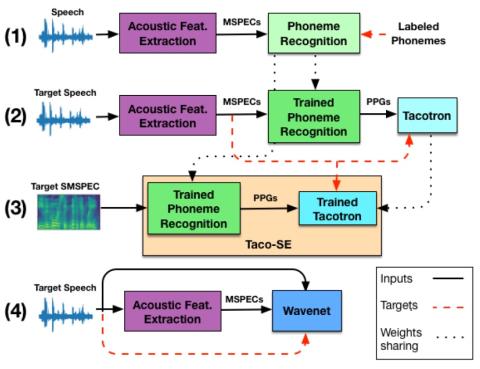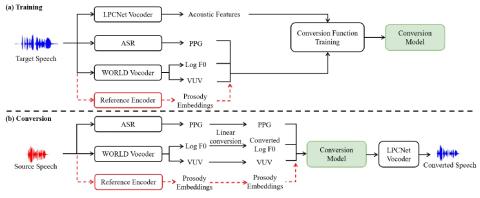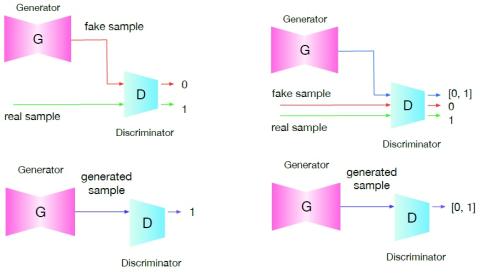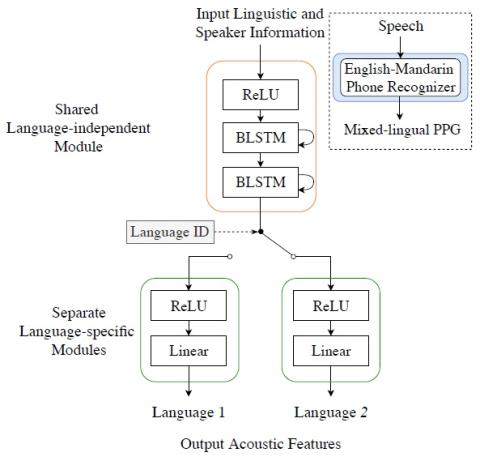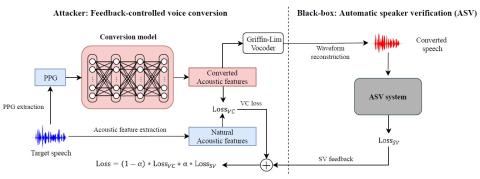
Атаки "черного ящика" на автоматическую проверку говорящего с помощью преобразования голоса с обратной связью
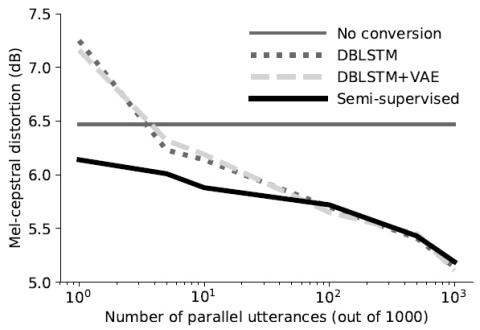
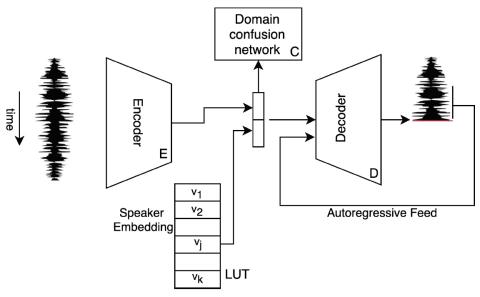
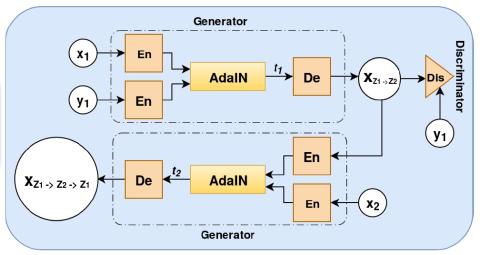
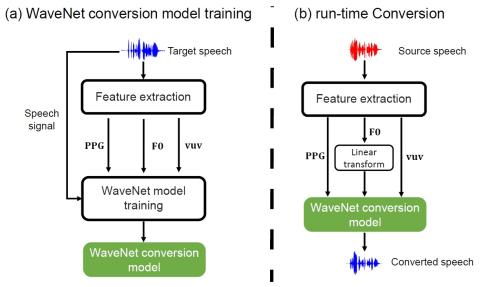
Системы автоматической проверки диктора (ASV) на практике очень уязвимы к атакам подмены. Новейшие технологии преобразования голоса позволяют воспроизводить естественную для восприятия речь, имитирующую речь любого целевого носителя. Однако для того, чтобы обмануть систему ASV, может быть недостаточно точности восприятия личности говорящего. В этой работе мы предлагаем структуру, которая использует выходные данные системы ASV в качестве обратной связи с системой преобразования голоса. Платформа attacker framework - это черный ящик злоумышленника, который крадет голосовую идентификацию пользова...