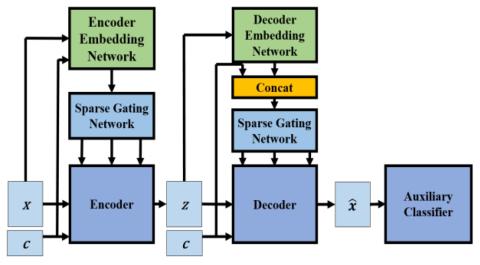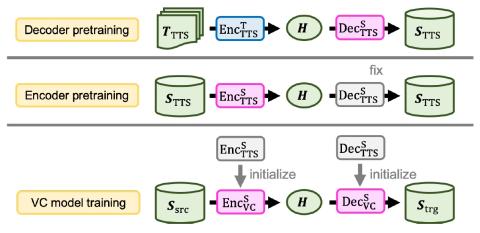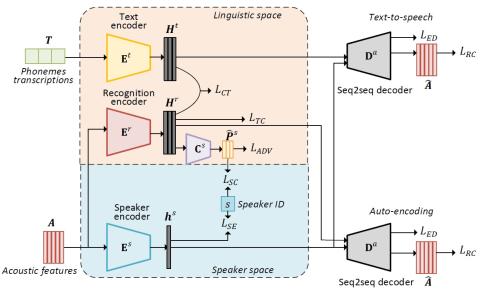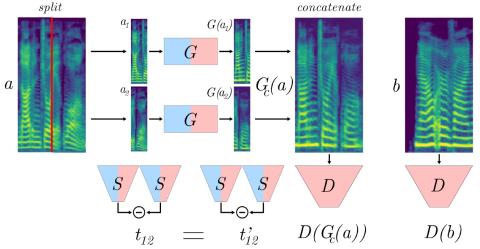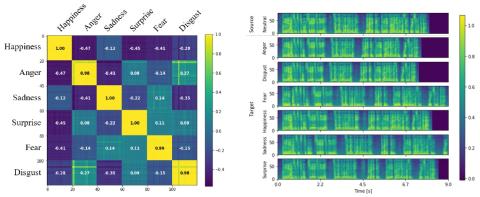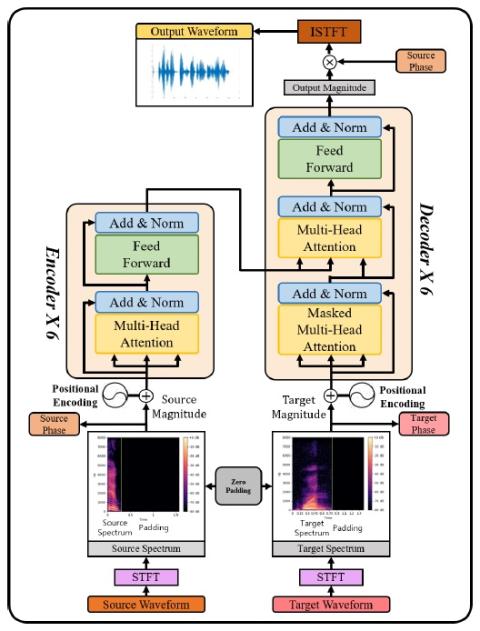
Сквозное преобразование голоса без вокодера с помощью трансформаторной сети
Подходы, основанные на использовании банка частотных фильтров Mel (MFB), имеют преимущество в изучении речи по сравнению с необработанным спектром, поскольку MFB имеет меньший размер элемента. Однако для создания генератора речи с использованием методов MFB требуется дополнительный вокодер, что требует огромных вычислительных затрат для процесса обучения. Дополнительная предварительная/постобработка, такая как MFB и вокодер, не обязательна для преобразования реальной человеческой речи в другие звуки. Можно использовать только необработанный спектр вместе с фазой, чтобы генерировать голоса друг...