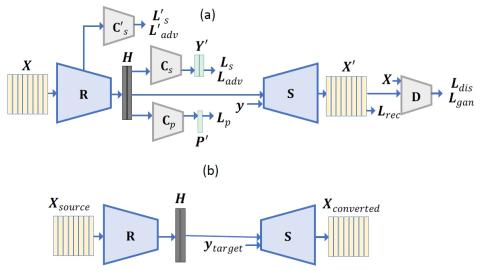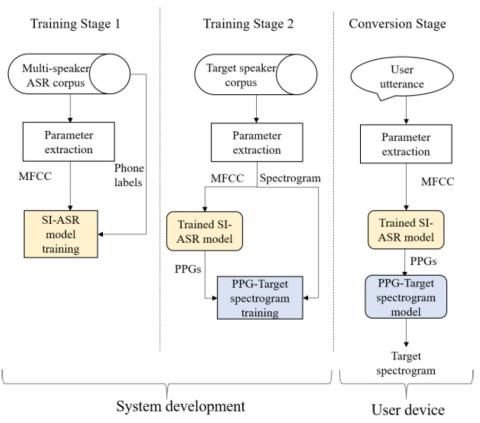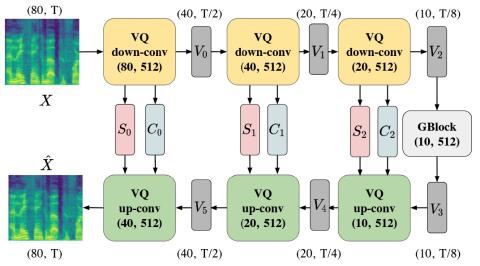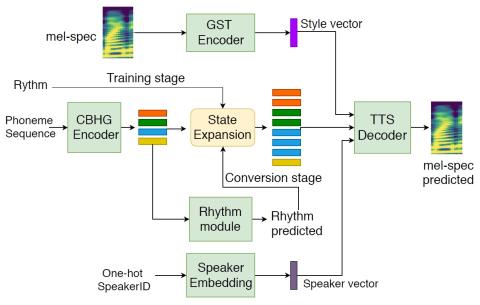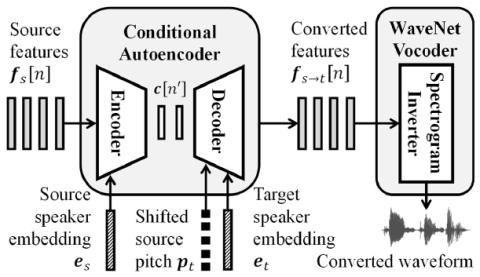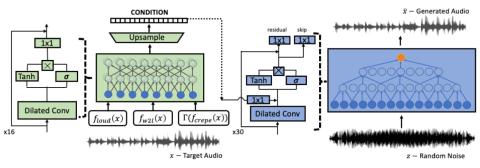
Неконтролируемое междоменное преобразование певческого голоса
Мы представляем генерирующую модель wav-to-wav для задачи преобразования певческого голоса из любого идентификатора. Наш метод использует как акустическую модель, обученную для задачи автоматического распознавания речи, так и функции извлечения мелодии для управления генератором на основе формы сигнала. Предлагаемая генеративная архитектура инвариантна к личности говорящего и может быть обучена генерировать целевых исполнителей на основе немаркированных обучающих данных, используя либо речевые, либо певческие источники. Модель оптимизируется сквозным образом без какого-либо ручного контроля, т...