Мы представляем подход к синтезу шепота, применяя разработанный вручную рецепт обработки сигналов и методы преобразования голоса для преобразования обычной фонетической речи в речь шепотом. Мы исследуем, используя модели гауссовой смеси (GMM) и глубокие нейронные сети (DNN), чтобы смоделировать соответствие между акустическими характеристиками обычной речи и речи шепотом. Мы оцениваем естественность и сходство с диктором преобразованного шепота во внутреннем корпусе и в общедоступном корпусе wTIMIT. Мы показываем, что применение методов преобразования голоса значительно эффективнее, чем использование методов обработки сигналов, основанных на правилах, и позволяет получить результаты, неотличимые от синтеза копий записей естественного шепота. Мы исследуем способность модели DNN обобщать данные о невидимых говорящих при обучении на данных от нескольких говорящих. Мы показываем, что исключение целевого говорящего из обучающей выборки практически не влияет на воспринимаемую естественность и сходство между говорящими преобразованного шепота. Предложенный метод DNN используется в недавно выпущенном режиме шепота Amazon Alexa.
Выводы
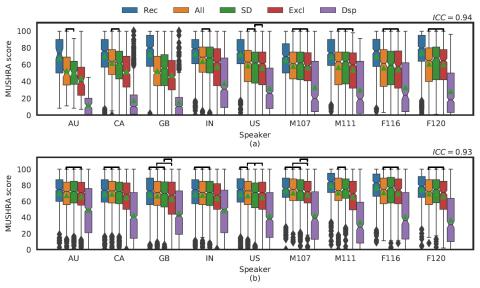
Насколько нам известно, эта статья была первым исследованием, в котором была предпринята попытка преобразовать нормальную речь в речь шепотом. Для достижения этой цели мы использовали обработку сигналов и два метода преобразования голоса (основанные на моделях GMM и DNN). Мы оценили три метода как на внутреннем корпусе, так и на общедоступном корпусе timit.
Мы обнаружили, что технология DSP обеспечивает высокую производительность для всех говорящих обоих корпусов, однако она далека от теоретического предела, установленного вокодером. Однако все методы преобразования голоса превзошли систему DSP по естественности, разборчивости и сходству характеристик говорящих. Они достигли технического предела, установленного вокодером и цепочкой выделения признаков. Мы показали, что модели DNN могут изучать отображение, не зависящее от говорящего, при обучении на нескольких говорящих и что они способны обобщать и воспроизводить речь шепотом для невидимых носителей. Мы обнаружили, что модели DNN могут быть устойчивы к условиям регистрации, если они обучены на основе достаточно разнообразных данных. Модель DNN не может быть обобщена для разных полов, и для межгендерных приложений рекомендуется использовать сбалансированный по гендерному признаку корпус. Предложенный метод DNN был интегрирован в Amazon Alexa и используется для генерации выходных данных для недавно выпущенного режима Whisper.