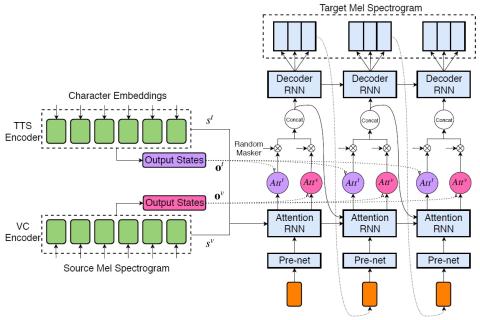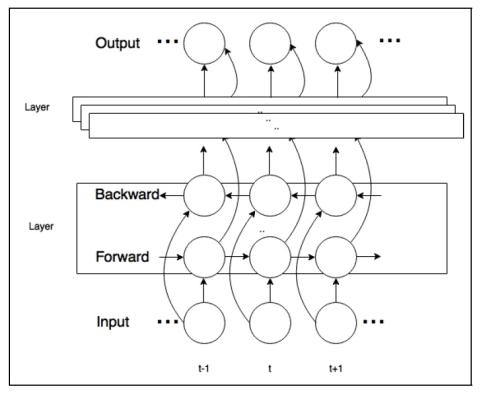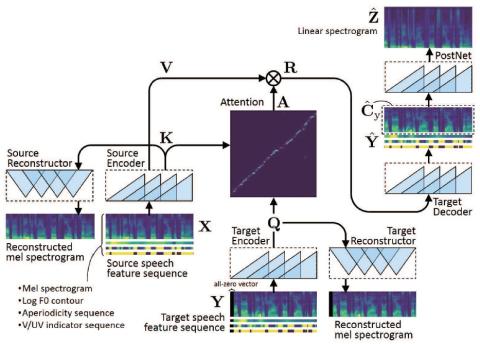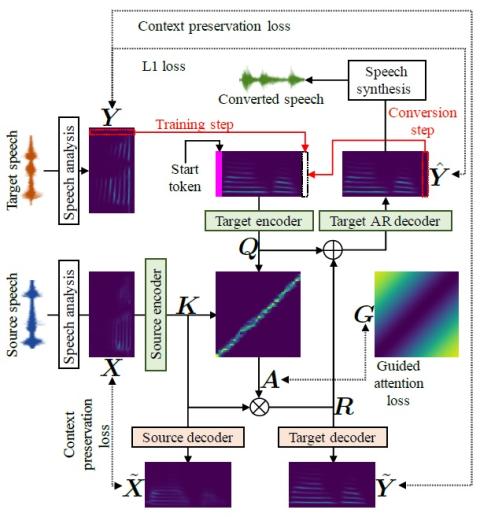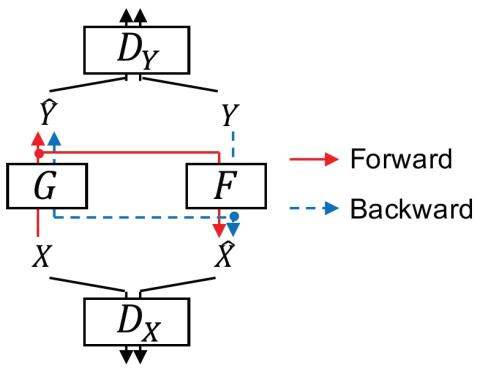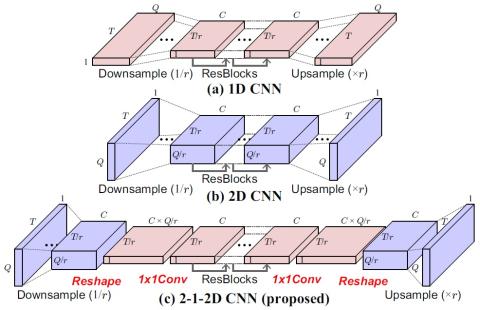
CycleGAN-VC2: Улучшенное непараллельное преобразование голоса на основе Cycle GAN
Непараллельное преобразование голоса - это метод преобразования исходной речи в целевую, не полагаясь на параллельные данные. Это важная задача, но она была сложной из-за недостатков условий обучения. Недавно CycleGAN-VC совершил прорыв и сравним с параллельным методом преобразования голоса, не прибегая к каким-либо дополнительным данным, модулям или процедурам выравнивания по времени. По-прежнему существует большой разрыв между реальным целевымй и преобразованным голосом, и преодоление этого разрыва остается сложной задачей. Чтобы сократить этот разрыв, мы предлагаем CycleGAN-VC2, который явл...