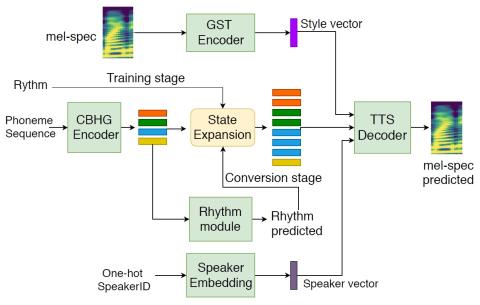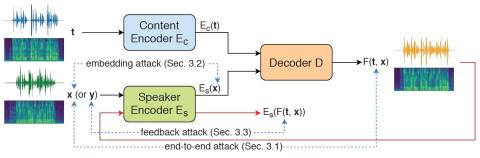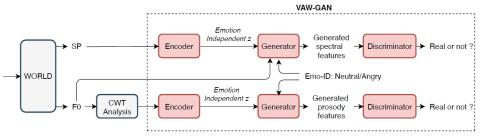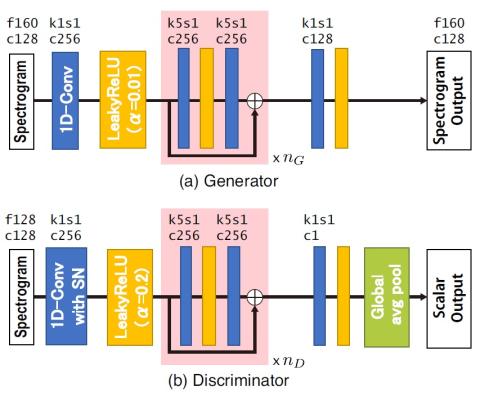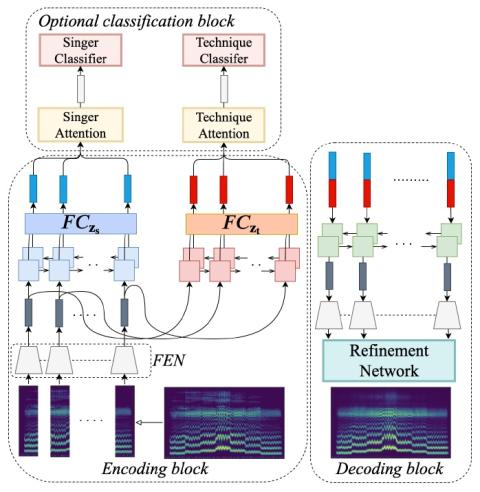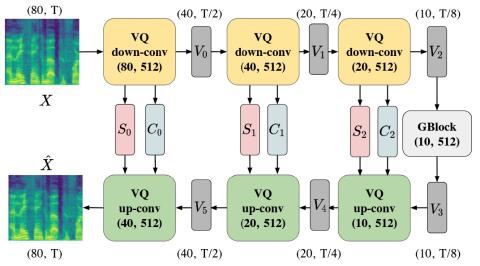
VQVC+: Одноразовое преобразование голоса с помощью векторного квантования и архитектуры U-Net
Преобразование голоса (VC) - это задача, которая преобразует тембр, акцент и тона исходного говорящего в аудио в другой звук, сохраняя при этом лингвистическое содержание. Это все еще сложная работа, особенно в условиях одного прохода. Методы преобразования голоса , основанные на автокодировщике, распутывают говорящего и содержание входной речи без указания личности говорящего, поэтому эти методы могут далее обобщаться на невидимых говорящих. Возможность распутывания достигается векторным квантованием (VQ), состязательным обучением или нормализацией экземпляра (IN). Однако несовершенное распут...