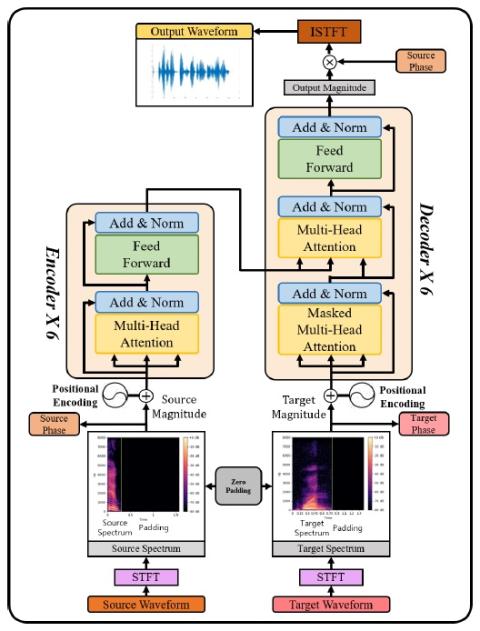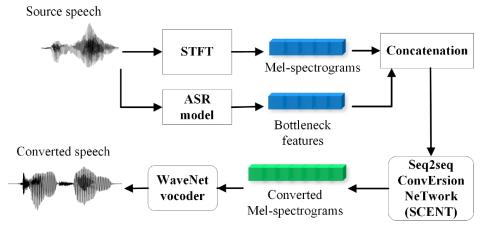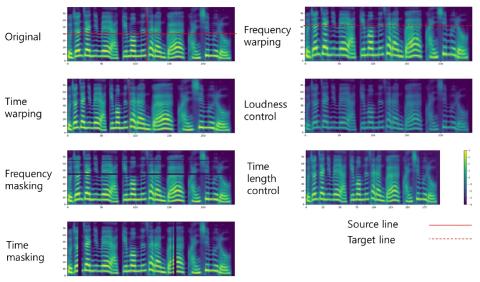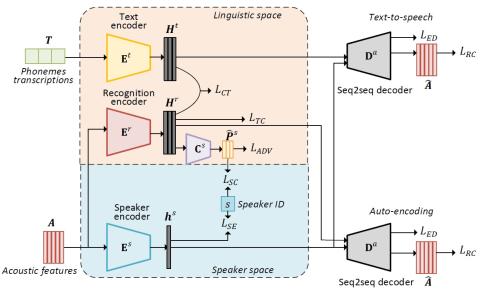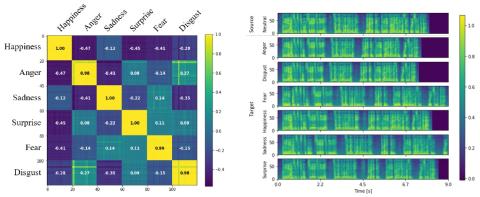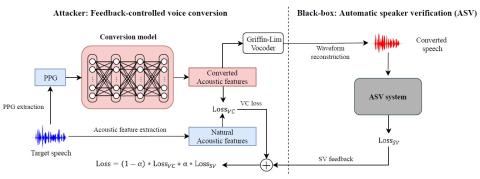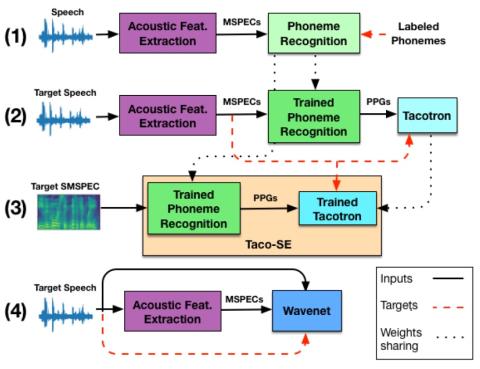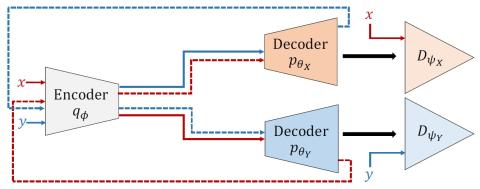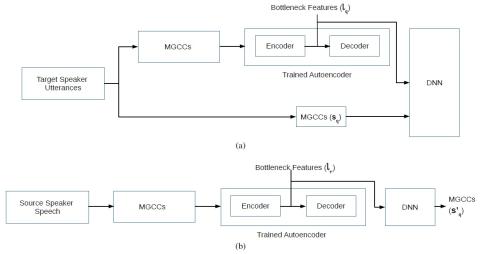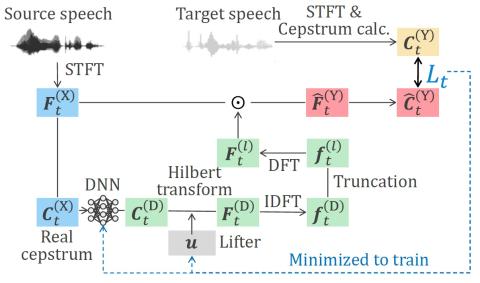
Обучение лифтеров и моделирование поддиапазонов для эффективного с точки зрения вычислений и высококачественного преобразования голоса с использованием спектральных различий
В этой статье мы предлагаем эффективные с точки зрения вычислений и высококачественные методы статистического преобразования голоса (VC) с прямой модификацией формы сигнала на основе спектральных различий. Традиционный метод с фильтром минимальной фазы обеспечивает высококачественное преобразование, но требует больших вычислений при фильтрации. Это связано с тем, что минимальная фаза с использованием фиксированного лифтера в преобразовании Гильберта часто приводит к фильтру с длинным нажатием. Один из наших методов - это метод обучения атлета, основанный на данных. Поскольку этот метод учитыва...