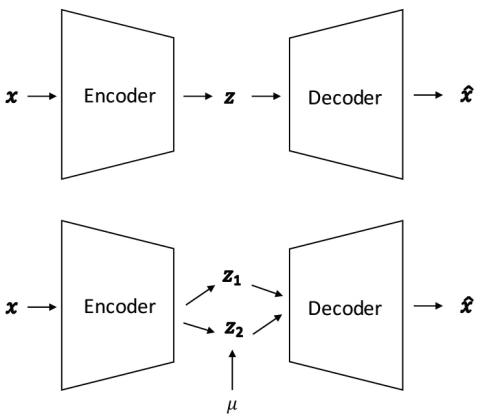
Мы изучаем проблему межъязыкового преобразования голоса в непараллельных речевых корпусах и в условиях однократного обучения. Для большинства предварительных работ требуются либо параллельные речевые корпуса, либо достаточное количество обучающих данных от целевого носителя. Однако мы преобразуем произвольные предложения произвольного исходного диктора в целевое высказывание целевого диктора, учитывая только одно тренировочное высказывание целевого диктора. Чтобы достичь этого, мы формулируем задачу как изучение неразборчивых представлений, специфичных для говорящего и контекста, и следуем идее [1], в которой используется факторизованный иерархический вариационный автоэнкодер (FHVAE). После обучения FHVAE на основе обучающих данных для нескольких дикторов, учитывая произношение произвольного источника и целевого носителя, мы оцениваем эти скрытые представления и затем восстанавливаем желаемое произношение преобразованного голоса в соответствии с произношением целевого носителя. Мы исследовали эффективность этого подхода, проводя эксперименты по преобразованию голоса с различным размером обучающих фраз, и нам удалось добиться приемлемой производительности даже при использовании всего одной обучающей фразы. Мы также исследуем речевое представление и показываем, что World vocoder превосходит кратковременное преобразование Фурье (STFT), используемое в [1]. Наконец, в субъективных тестах для преобразования речи на одном языке и на разных языках наш подход позволил получить значительно лучшие или сопоставимые результаты по качеству и сходству речи по сравнению с базовыми показателями VAE-STFT и GMM.
Выводы
Мы предложили использовать модель FHVAE для сложного непараллельного и межъязыкового преобразования голоса даже при очень небольшом количестве обучающих высказываний, например, при произнесении только одного целевого диктора. Мы исследовали важность представления речи и обнаружили, что World vocoder превзошел STFT, который использовался в [1] при экспериментальной оценке, как по качеству речи, так и по сходству. Мы также изучили влияние размера обучающих фраз целевого диктора на преобразование голоса, и наш подход превзошел базовый уровень при использовании менее 10 предложений и позволил добиться приемлемой производительности даже при использовании всего одной обучающей фразы. В субъективных тестах наш подход показал значительно лучшие результаты, чем VAE-STFT и GMM, по качеству речи, а также превзошел VAE-STFT и сравним с GMM по сходству речи. В качестве будущей работы мы заинтересованы в совместном сквозном обучении с Wavenet или Wavenet-vocoder и работаем над этим, а также над созданием моделей, обученных многоязычным корпусам, с явным моделированием различных языков или без него, например, с обеспечением языкового кодирования.