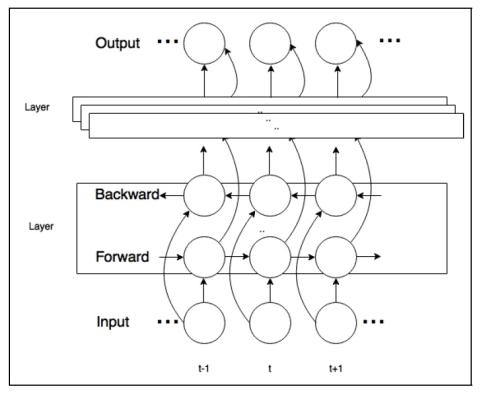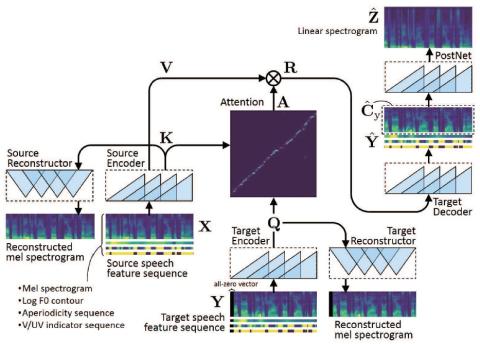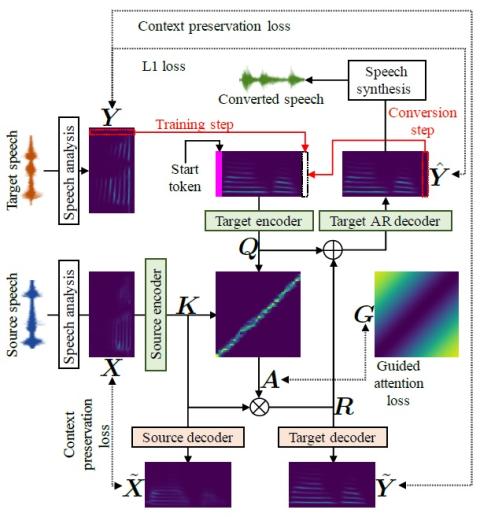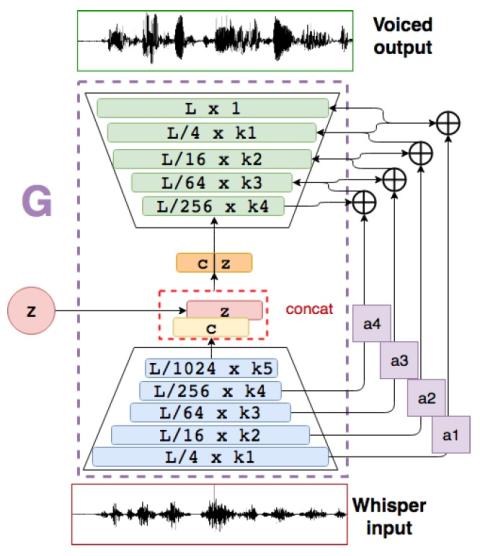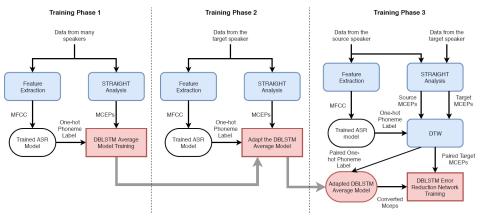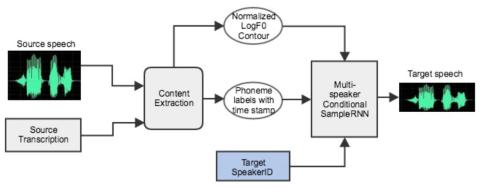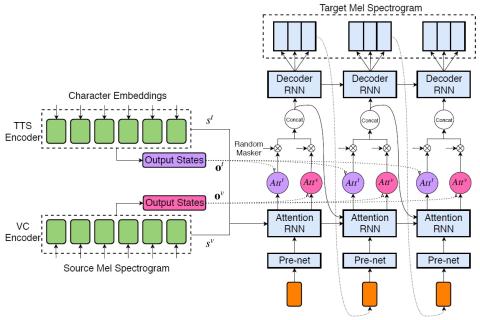
Joint training framework for text-to-speech and voice conversion using multi-source Tacotron and WaveNet
We investigated the training of a shared model for both text-to-speech (TTS) and voice conversion (VC) tasks. We propose using an extended model architecture of Tacotron, that is a multi-source sequence-to-sequence model with a dual attention mechanism as the shared model for both the TTS and VC tasks. This model can accomplish these two different tasks respectively according to the type of input. An end-to-end speech synthesis task is conducted when the model is given text as the input while a sequence-to-sequence voice conversion task is conducted when it is given the speech of a source spea...