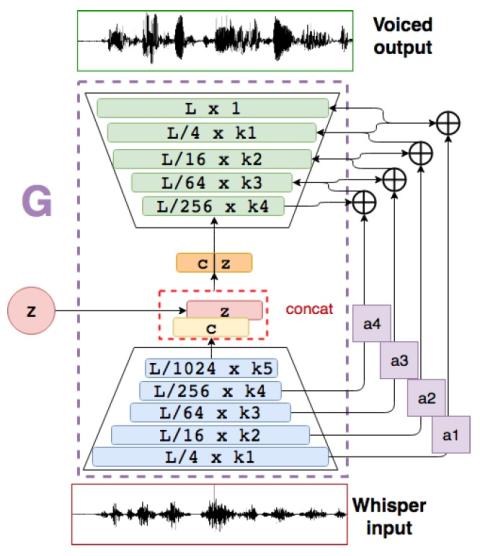
Most methods of voice restoration for patients suffering from aphonia either produce whispered or monotone speech. Apart from intelligibility, this type of speech lacks expressiveness and naturalness due to the absence of pitch (whispered speech) or artificial generation of it (monotone speech). Existing techniques to restore prosodic information typically combine a vocoder, which parameterises the speech signal, with machine learning techniques that predict prosodic information. In contrast, this paper describes an end-to-end neural approach for estimating a fully-voiced speech waveform from whispered alaryngeal speech. By adapting our previous work in speech enhancement with generative adversarial networks, we develop a speaker-dependent model to perform whispered-to-voiced speech conversion. Preliminary qualitative results show effectiveness in re-generating voiced speech, with the creation of realistic pitch contours.
Conclusions
We presented a speaker-dependent end-to-end generative adversarial network to act as a post-filter of whispered speech to deal with a pathological application. We adapted our previous speech enhancement GAN architecture to overcome misalignment issues and still obtained a stable GAN architecture to reconstruct voiced speech. The model is able to generate novel pitch contours by only seeing the whispered version of the speech at its input. The method generates richer curves than the baseline, which sounds monotonic in terms of prosody. Future lines of work include an even more end-to-end approach by going sensor-to-speech. Also, further study is required to alleviate intrinsic high frequency artifacts provoked by the type of decimation-interpolation architecture we base our design on.