An effective approach to non-parallel voice conversion (VC) is to utilize deep neural networks (DNNs), specifically variational auto encoders (VAEs), to model the latent structure of speech in an unsupervised manner. A previous study has confirmed the effectiveness of VAE using the STRAIGHT spectra for VC. However, VAE using other types of spectral features such as melcepstral coefficients (MCCs), which are related to human perception and have been widely used in VC, have not been properly investigated. Instead of using one specific type of spectral feature, it is expected that VAE may benefit from using multiple types of spectral features simultaneously, thereby improving the capability of VAE for VC. To this end, we propose a novel VAE framework (called cross-domain VAE, CDVAE) for VC. Specifically, the proposed framework utilizes both STRAIGHT spectra and MCCs by explicitly regularizing multiple objectives in order to constrain the behavior of the learned encoder and decoder. Experimental results demonstrate that the proposed CDVAE framework outperforms the conventional VAE framework in terms of subjective tests.
Discussion
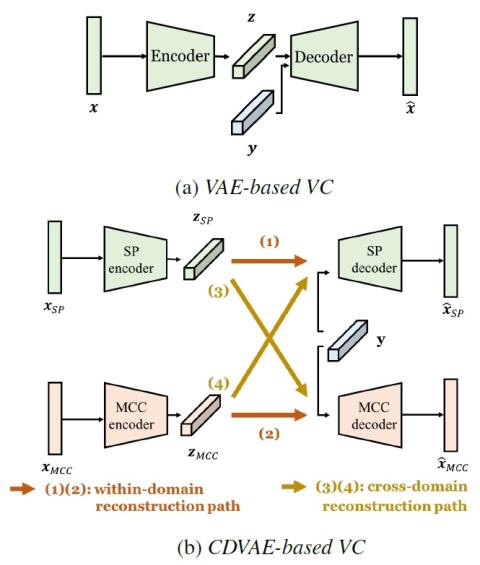
In Section 4, we have shown that our proposed CDVAE framework successfully utilizes cross-domain features to improve the capability of VAE for VC, and outperforms the baseline VAE-based VC system in the subjective tests. The question is: how does the underlying speech model benefit from our framework?
Recall that the viability of the VAE framework relies on the decomposition of input frames, which is assumed to be composed of a latent code (in VC, phonetic code or linguistic content) and a speaker code. Ideally, when applying VAE to VC, the latent code should contain solely the phonetic information of the frame, with no information about the speaker. However, this decomposition is not explicitly guaranteed. Hand-crafted features like SP or MCCs possess their own natures, thus even for the same input frame, the required information to reconstruct the inputs from different feature domains may differ. When trained with one feature alone, only the necessary information to reconstruct that feature is left in the latent code, thus the VAE framework might fit the property of that specific feature too well, losing the generalization ability. One way to reinforce decomposition is to involve as many speakers as possible during training, which may not necessarily lead to better decomposition. Our proposed framework forces the encoder to act more like a speaker-independent phone recognizer, thus filters out unnecessary, speaker-dependent information of the input feature. As a result, our framework not only achieves cross-domain feature property satisfaction, but learns more disentangled latent representation of speech.
In the future, we plan to investigate in detail the above assumption. In addition, Wasserstein generative adversarial network (WGAN) [24] has been introduced to the conventional VAE-based VC method [18] for improving the naturalness of converted speech, so we also plan to introduce WGAN to the proposed framework.