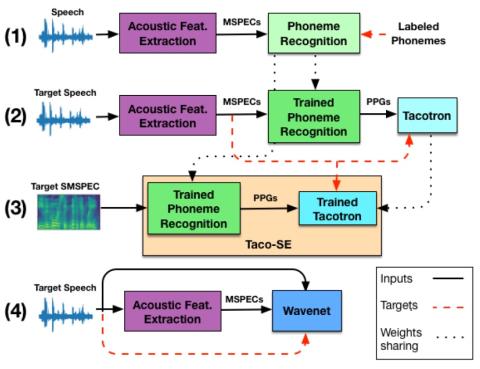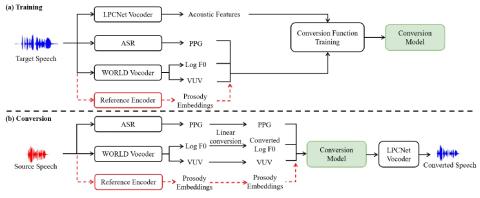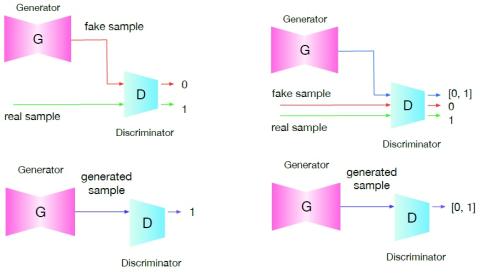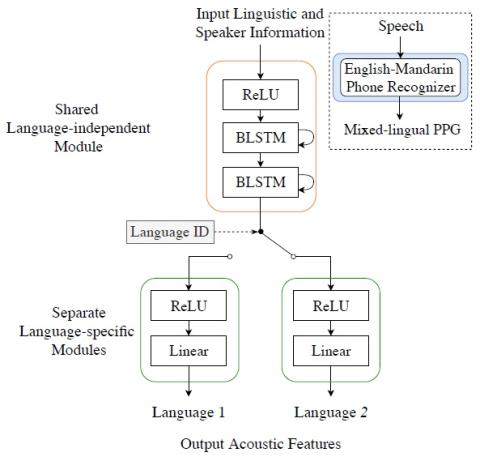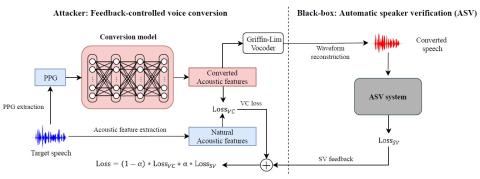
Black-box Attacks on Automatic Speaker Verification using Feedback-controlled Voice Conversion
Automatic speaker verification (ASV) systems in practice are greatly vulnerable to spoofing attacks. The latest voice conversion technologies are able to produce perceptually natural sounding speech that mimics any target speakers. However, the perceptual closeness to a speaker's identity may not be enough to deceive an ASV system. In this work, we propose a framework that uses the output scores of an ASV system as the feedback to a voice conversion system. The attacker framework is a black-box adversary that steals one's voice identity, because it does not require any knowledge about the ASV ...