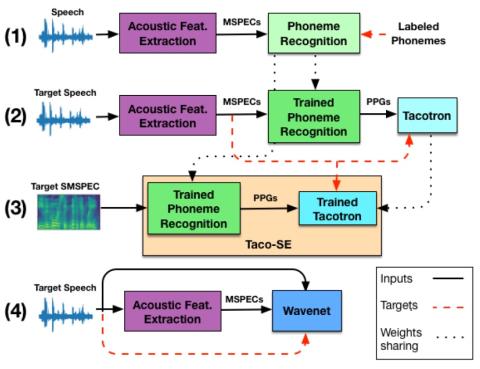
This paper introduces Taco-VC, a novel architecture for voice conversion (VC) based on the Tacotron synthesizer, which is a sequence-to-sequence with attention model. The training of multi-speaker voice conversion systems requires a large amount of resources, both in training and corpus size. Taco-VC is implemented using a single speaker Tacotron synthesizer based on Phonetic Posteriorgrams (PPGs) and a single speaker Wavenet vocoder conditioned on Mel Spectrograms. To enhance the converted speech quality, the outputs of the Tacotron are passed through a novel speech-enhancement network, which is composed of a combination of phoneme recognition and Tacotron networks. Our system is trained just with a mid-size, single speaker corpus, and adapted to new speakers using only few minutes of training data. Using public mid-size datasets, our method outperforms the baseline in the VCC 2018 SPOKE task, and achieves competitive results compared to multi-speaker networks trained on private large datasets.
Conclusion
This paper presents Taco-VC, a voice conversion system comprised of phoneme recognition, Tacotron synthesizer, and Wavenet vocoder. We introduce the speech enhancement network, which might be of interest by itself, and describe how to enhance the synthesized Mel-Spectrograms only using the trained networks. We show in the MOS experiments that our architecture, using public single speaker, mid-size training sets, can adapt to other targets with limited training sets, using only a single speaker system, and provide competitive results compared to multi-speaker VC systems trained on private and much larger datasets.
We believe that the high error rate of the phoneme recognition network has a large impact on the converted speech. As a future work, we suggest adding more acoustic features to the generated PPGs, such as F0 and voice/unvoiced flag, or extracting PPGs from other speech recognition networks with lower error rates. In addition, our results indicate that training on a single female speaker might be insufficient for adapting to male targets. Therefore, adding training on a single male speaker can be helpful for this case. It might be worthwhile also to explore in future work, the effect of an adversarial loss on our system. Another possible future research direction is applying the Taco-SE architecture (with a corresponding Wavenet for denoising) to speech denoising tasks.