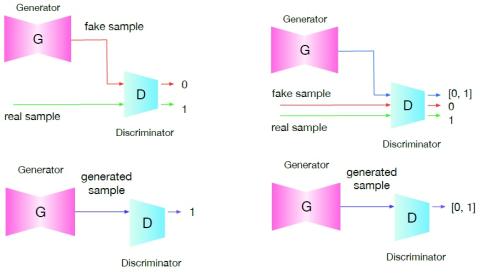
Voice conversion with deep neural networks has become extremely popular over the last few years with improvements over the past VC architectures. In particular, GAN architectures such as the cycleGAN and the VAEGAN have offered the possibility to learn voice conversion from non-parallel databases. However, GAN-based methods are highly unstable, requiring often a careful tuning of hyper-parameters, and can lead to poor voice identity conversion and substantially degraded converted speech signal. This paper discusses and tackles the stability issues of the GAN in the context of voice conversion. The proposed SoftGAN method aims at reducing the impact of the generator on the discriminator and vice versa during training, so both can learn more gradually and efficiently during training, in particular avoiding a training not in tandem. A subjective experiment conducted on a voice conversion task on the voice conversion challenge 2018 dataset shows that the proposed SoftGAN significantly improves the quality of the voice conversion while preserving the naturalness of the converted speech.
Conclusion
The present paper investigates into Voice Conversion with GAN. To address the stability issue of the GAN training we propose to use soft training labels that are influenced by the discriminator output, and we investigate into using an additional energy attribute attribute constraint providing a more stable objective to the generator. Using these means, we built a rather small generator with only a few layers. Our conducted experiment shows that the SoftGAN training was able to stabilize the small network, that was otherwise not converging to produce useful sound, achieving a similarity score of 3.40 +/- 0.40 and a naturalness score of 3.02 +/- 0.35 in a MOS scale. Using a larger network, both the naturalness and the similarity were 0.5 MOS points bellow our SoftGAN results. Furthermore, the experimental results confirm the beneficial impact of the energy constraint can improve the similarity and the naturalness of VC by again 0.5 MOS points. The experimental results seem to confirm our hypothesis that smaller networks can be beneficial for training VC networks when only small training databases are available. Finally, we hope that this innovative GAN technique might be beneficial for other applications.