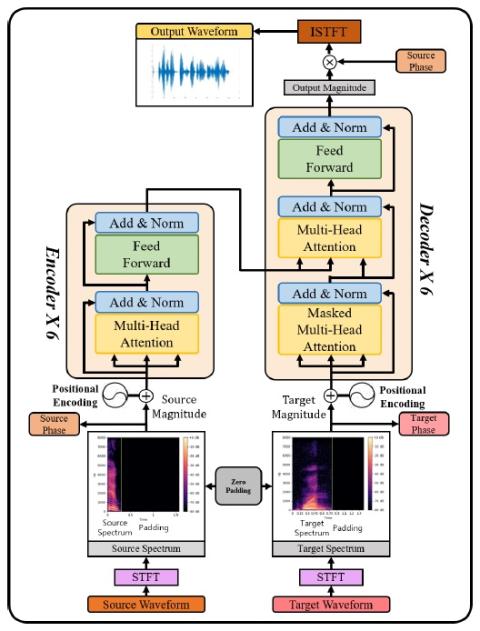
Vocoder-free End-to-End Voice Conversion with Transformer Network
Mel-frequency filter bank (MFB) based approaches have the advantage of learning speech compared to raw spectrum since MFB has less feature size. However, speech generator with MFB approaches require additional vocoder that needs a huge amount of computation expense for training process. The additional pre/post processing such as MFB and vocoder is not essential to convert real human speech to others. It is possible to only use the raw spectrum along with the phase to generate different style of voices with clear pronunciation. In this regard, we propose a fast and effective approach to convert...