Voice conversion (VC) is a task to transform a person's voice to different style while conserving linguistic contents. Previous state-of-the-art on VC is based on sequence-to-sequence (seq2seq) model, which could mislead linguistic information. There was an attempt to overcome it by using textual supervision, it requires explicit alignment which loses the benefit of using seq2seq model. In this paper, a voice converter using multitask learning with text-to-speech (TTS) is presented. The embedding space of seq2seq-based TTS has abundant information on the text. The role of the decoder of TTS is to convert embedding space to speech, which is same to VC. In the proposed model, the whole network is trained to minimize loss of VC and TTS. VC is expected to capture more linguistic information and to preserve training stability by multitask learning. Experiments of VC were performed on a male Korean emotional text-speech dataset, and it is shown that multitask learning is helpful to keep linguistic contents in VC.
Conclusion
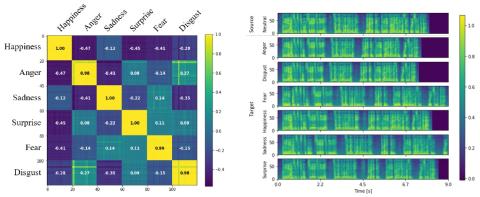
In this paper, we presented emotional VC using multitask learning with TTS. Although there have been abundant researches on VC, the performance of VC lacks in terms of preserving linguistic information, emotional, and many-to-many VC. Unlike previous methods, the linguistic contents of VC are preserved by multitask learning with TTS. A single model is trained to optimize on both VC and TTS, the embedding space is trained to capture linguistic information by TTS. The result shows that using multitask learning much reduces WER, and subjective evaluation also supports this. For emotional VC, we collected a Korean parallel database for seven distinct emotions, and the model is trained to generate speech depends on the style reference input. Also, style encoder is devised to extract style information while removing linguistic information. Without explicit input of emotion label, style encoder successfully disentangles emotions.
This research can be extended to many other directions. First, we only show the possibility of helping TTS to VC, but TTS can be also improved by VC since some language has highly nonlinear relationship between text and its pronunciation. Second, the contents encoder is trained to extract only linguistic information, it could be extended to improve speech recognition. Third, more explicit loss such as domain adversarial loss can be added to minimize the difference between embedding of VC and TTS in linguistic space.