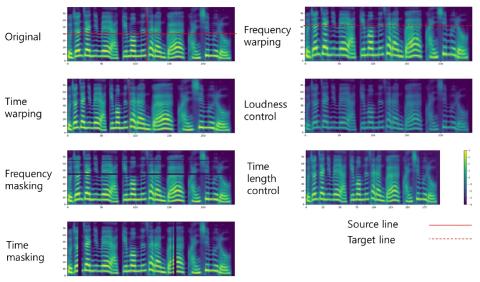
When training the sequence-to-sequence voice conversion model, we need to handle an issue of insufficient data about the number of speech tuples which consist of the same utterance. This study experimentally investigated the effects of Mel-spectrogram augmentation on the sequence-to-sequence voice conversion model. For Mel-spectrogram augmentation, we adopted the policies proposed in SpecAugment. In addition, we propose new policies for more data variations. To find the optimal hyperparameters of augmentation policies for voice conversion, we experimented based on the new metric, namely deformation per deteriorating ratio. We observed the effect of these through experiments based on various sizes of training set and combinations of augmentation policy. In the experimental results, the time axis warping based policies showed better performance than other policies.
Conclusion
This paper describes the effect of Mel-spectrogram augmentation on the one-to-one Seq2Seq VC model. We adopted policies from SpecAugment and proposed new policies for Mel-spectrogram augmentation. We selected appropriate hyperparameters for each policy through experiments based on our proposed DPD metric. The experimental results showed that the relationship between the size of the training data and the linguistic expressiveness of the VC model is directly proportional. In addition, the policies based on the time axis warping showed lower CER than other policies. These results indicate that the use of policies based on the time axis warping is more efficiently training for developing the VC model with the insufficiency size of training set.