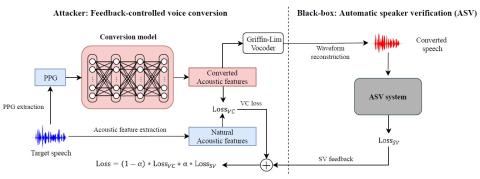
Automatic speaker verification (ASV) systems in practice are greatly vulnerable to spoofing attacks. The latest voice conversion technologies are able to produce perceptually natural sounding speech that mimics any target speakers. However, the perceptual closeness to a speaker's identity may not be enough to deceive an ASV system. In this work, we propose a framework that uses the output scores of an ASV system as the feedback to a voice conversion system. The attacker framework is a black-box adversary that steals one's voice identity, because it does not require any knowledge about the ASV system but the system outputs. Experimental results conducted on ASVspoof 2019 database confirm that the proposed feedback-controlled voice conversion framework produces adversarial samples that are more deceptive than the straightforward voice conversion, thereby boosting the impostor ASV scores. Further, the perceptual evaluation studies reveal that converted speech does not adversely affect the voice quality from the baseline system.
Conclusions
In this work, we study black-box attacks on ASV systems with a feedback-controlled VC system. Although the vulnerability traditional spoofing attacks to ASV has been established, the black-box attacks to machine learning poise a greater threat. We use ASV system outputs as the feedback to increase the deceptiveness of the converted voice. The studies conducted on ASVspoof 2019 corpus suggest that the proposed feedback-controlled VC system is able to enhance the ASV scores of the converted speech that makes it more deceptive towards authentication against the target speakers. Moreover, according to the subjective test results, we find that feedback-controlled VC maintains the performance in terms of speech quality and speaker similarity for the generated speech.