Towards Fine-Grained Prosody Control for Voice Conversion
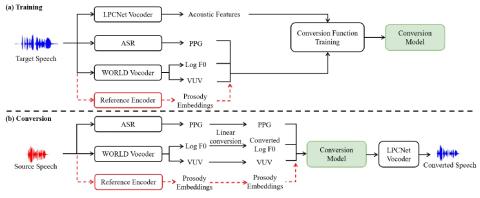
In a typical voice conversion system, prior works utilize various acoustic features (e.g., the pitch, voiced/unvoiced flag, aperiodicity) of the source speech to control the prosody of generated waveform. However, the prosody is related with many factors, such as the intonation, stress and rhythm. It is a challenging task to perfectly describe the prosody through acoustic features. To deal with this problem, we propose prosody embeddings to model prosody. These embeddings are learned from the source speech in an unsupervised manner. We conduct experiments on our Mandarin corpus recoded by prof...