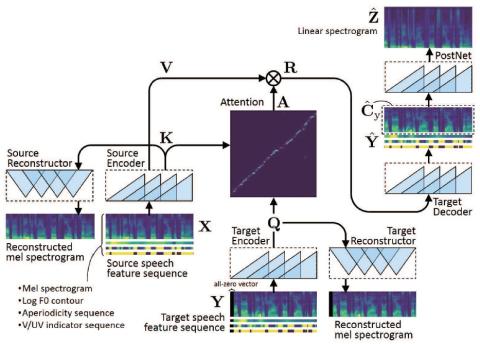
This paper proposes a voice conversion method based on fully convolutional sequence-to-sequence (seq2seq) learning. The present method, which we call "ConvS2S-VC", learns the mapping between source and target speech feature sequences using a fully convolutional seq2seq model with an attention mechanism. Owing to the nature of seq2seq learning, our method is particularly noteworthy in that it allows the flexible conversion of not only the voice characteristics but also the pitch contour and duration of the input speech. The current model consists of six networks, namely source and target encoders, a target decoder, source and target reconstructors and a postnet, which are designed using dilated causal convolution networks with gated linear units. Subjective evaluation experiments revealed that the proposed method obtained higher sound quality and speaker similarity than a baseline method.
Conclusions
This paper proposed a VC method based on a fully convolutional seq2seq model, which we call “ConvS2S-VC”.
There is a lot of future work to be done. Although we chose only one conventional method as the baseline in the present experiment, we plan to compare our method with other state-of-the-art methods. In addition, we plan to conduct more thorough evaluations in order to validate each of the choices we made as regards our model, such as the network architecture, with or without the guided attention loss, and with or without the context preservation mechanism, and report the results in forthcoming papers. As with the best performing systems in VCC 2018, we are interested in incorporating the WaveNet vocoder into our system in place of the WORLD vocoder to realize further improvements in sound quality. Recently, we have also been developing a VC system using an LSTM-based seq2seq model in parallel with this work. It would be interesting to investigate which of the two methods performs better in a similar setting.