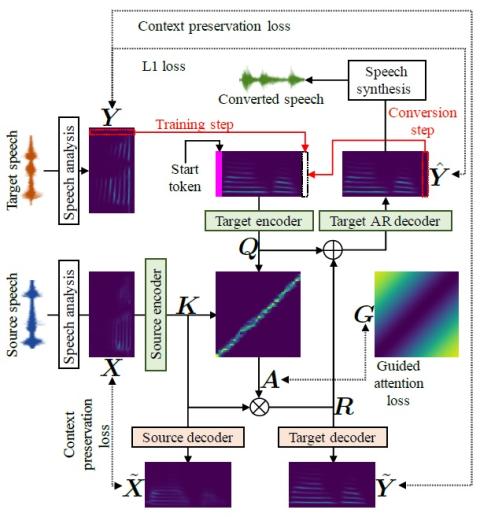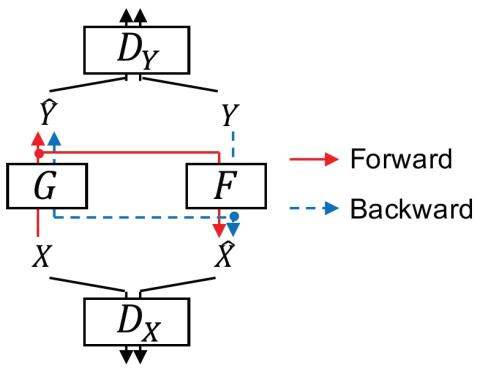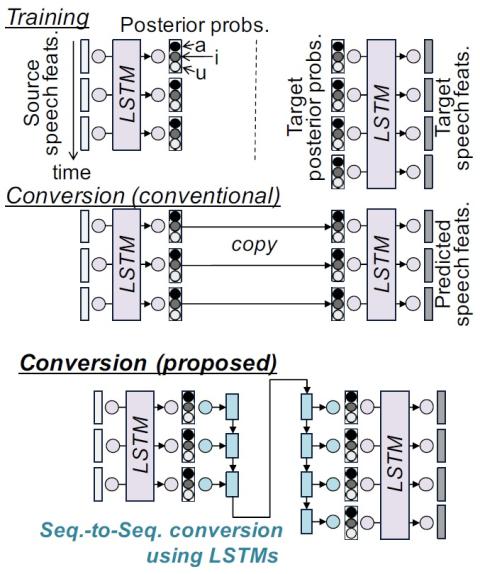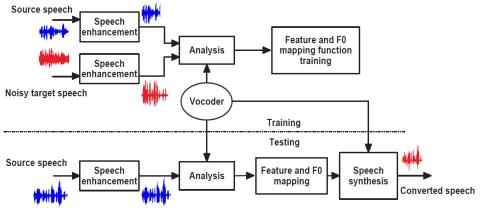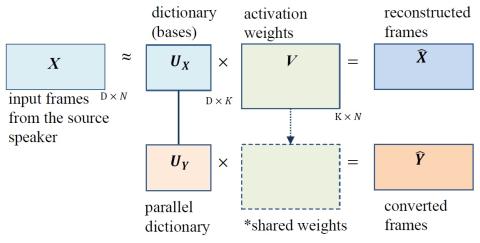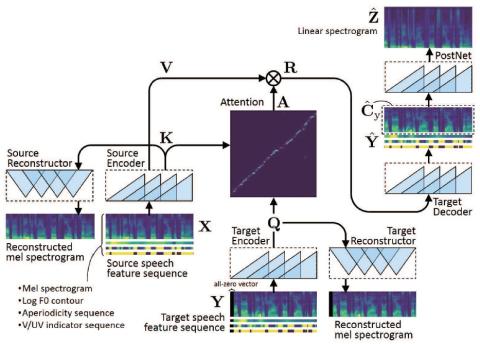
ConvS2S-VC: Fully convolutional sequence-to-sequence voice conversion
This paper proposes a voice conversion method based on fully convolutional sequence-to-sequence (seq2seq) learning. The present method, which we call "ConvS2S-VC", learns the mapping between source and target speech feature sequences using a fully convolutional seq2seq model with an attention mechanism. Owing to the nature of seq2seq learning, our method is particularly noteworthy in that it allows the flexible conversion of not only the voice characteristics but also the pitch contour and duration of the input speech. The current model consists of six networks, namely source and target encode...