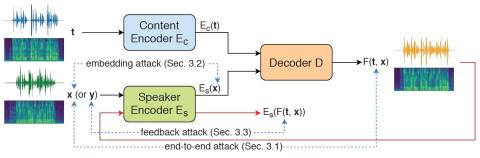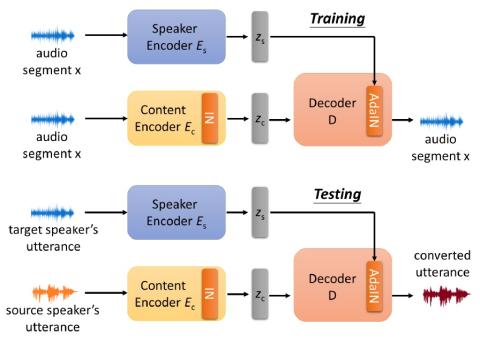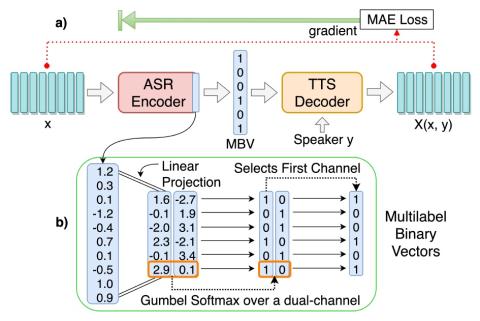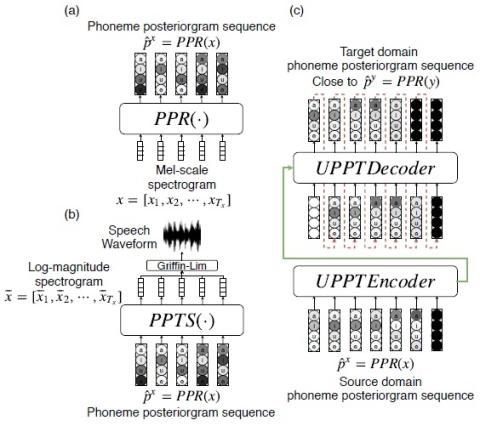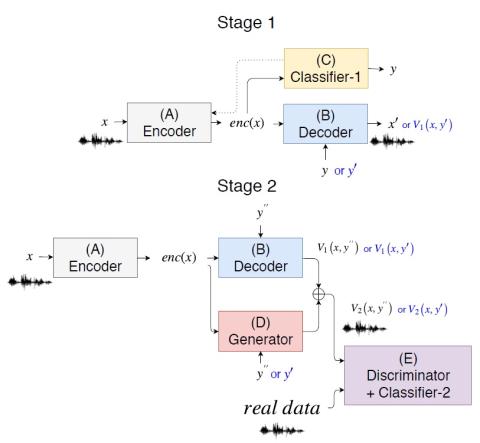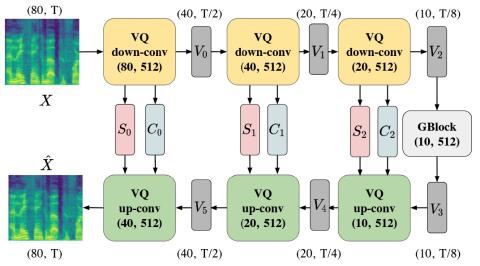
VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture
Voice conversion (VC) is a task that transforms the source speaker's timbre, accent, and tones in audio into another one's while preserving the linguistic content. It is still a challenging work, especially in a one-shot setting. Auto-encoder-based VC methods disentangle the speaker and the content in input speech without given the speaker's identity, so these methods can further generalize to unseen speakers. The disentangle capability is achieved by vector quantization (VQ), adversarial training, or instance normalization (IN). However, the imperfect disentanglement may harm the quality of o...