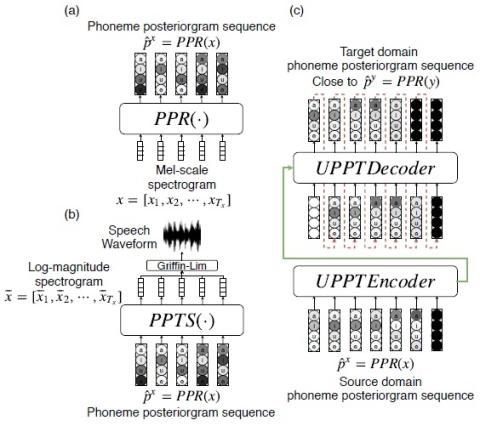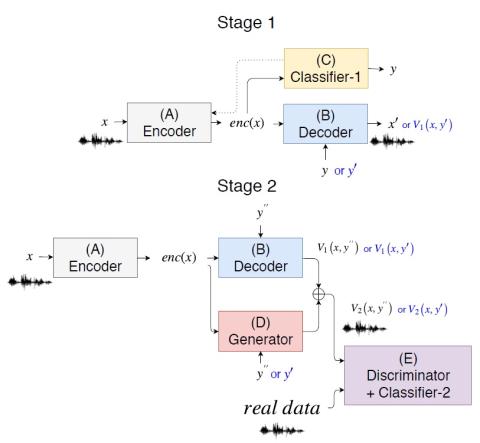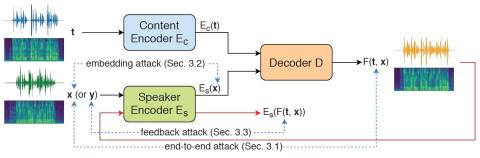
Defending Your Voice: Adversarial Attack on Voice Conversion
Substantial improvements have been achieved in recent years in voice conversion, which converts the speaker characteristics of an utterance into those of another speaker without changing the linguistic content of the utterance. Nonetheless, the improved conversion technologies also led to concerns about privacy and authentication. It thus becomes highly desired to be able to prevent one's voice from being improperly utilized with such voice conversion technologies. This is why we report in this paper the first known attempt to try to perform adversarial attack on voice conversion. We introduce...