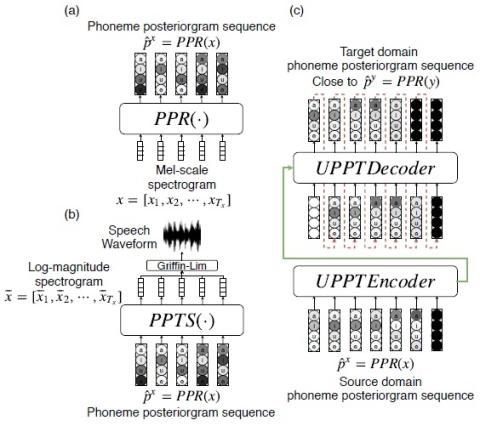
Speaking rate refers to the average number of phonemes within some unit time, while the rhythmic patterns refer to duration distributions for realizations of different phonemes within different phonetic structures. Both are key components of prosody in speech, which is different for different speakers. Models like cycle-consistent adversarial network (Cycle-GAN) and variational auto-encoder (VAE) have been successfully applied to voice conversion tasks without parallel data. However, due to the neural network architectures and feature vectors chosen for these approaches, the length of the predicted utterance has to be fixed to that of the input utterance, which limits the flexibility in mimicking the speaking rates and rhythmic patterns for the target speaker. On the other hand, sequence-to-sequence learning model was used to remove the above length constraint, but parallel training data are needed. In this paper, we propose an approach utilizing sequence-to-sequence model trained with unsupervised Cycle-GAN to perform the transformation between the phoneme posteriorgram sequences for different speakers. In this way, the length constraint mentioned above is removed to offer rhythm-flexible voice conversion without requiring parallel data. Preliminary evaluation on two datasets showed very encouraging results.
Conclusion
Objective and subjective evaluation on two different datasets showed that the proposed approach is able to mimic the voice characteristics of a target speaker, including the speaking rate and rhythmic patterns, without parallel data by utilizing sequence-to-sequence learning trained with Cycle-GAN to remove the length constraint. Although phoneme boundaries are needed for the training data, an easily obtained pretrained force-aligner can offer these boundaries.