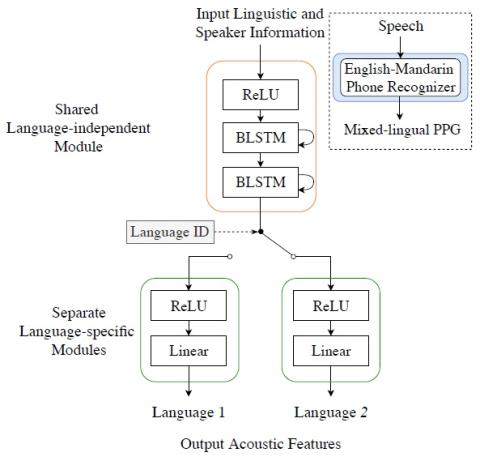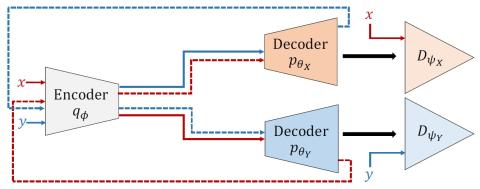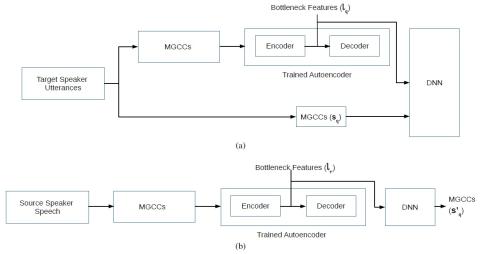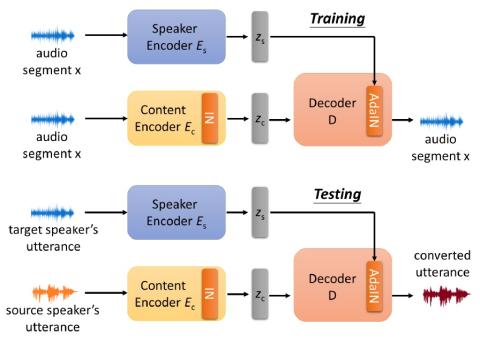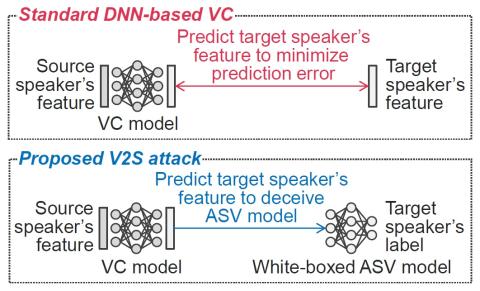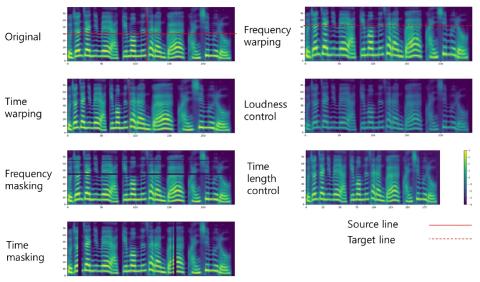
Mel-spectrogram augmentation for sequence to sequence voice conversion
When training the sequence-to-sequence voice conversion model, we need to handle an issue of insufficient data about the number of speech tuples which consist of the same utterance. This study experimentally investigated the effects of Mel-spectrogram augmentation on the sequence-to-sequence voice conversion model. For Mel-spectrogram augmentation, we adopted the policies proposed in SpecAugment. In addition, we propose new policies for more data variations. To find the optimal hyperparameters of augmentation policies for voice conversion, we experimented based on the new metric, namely deform...