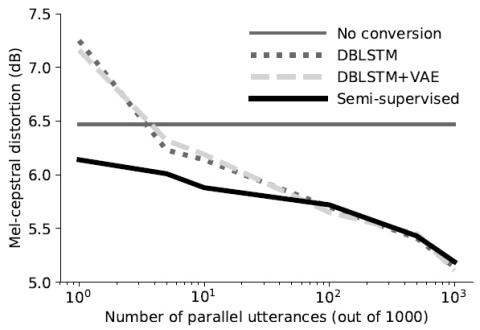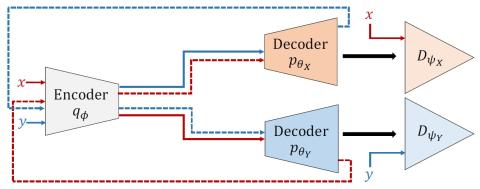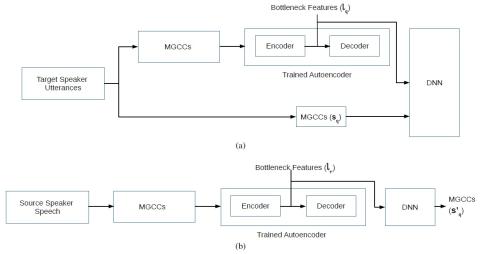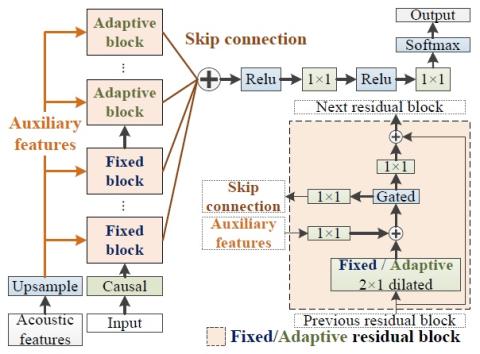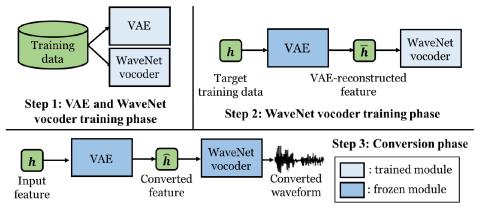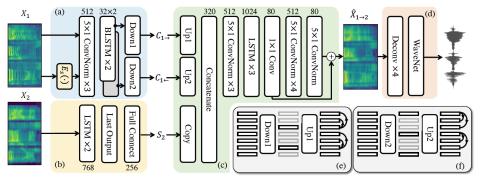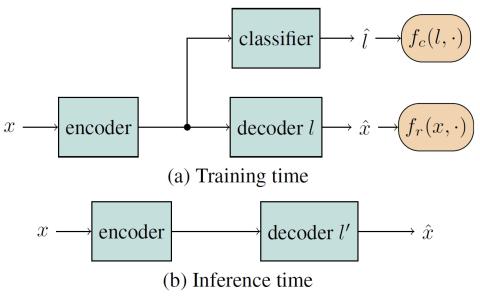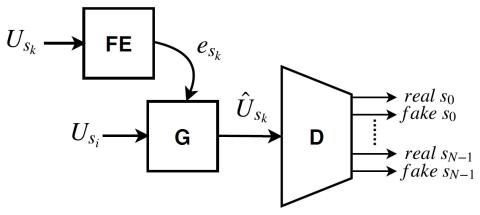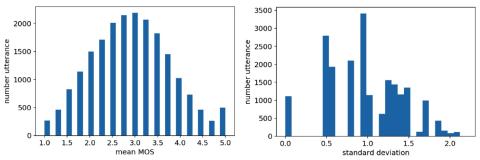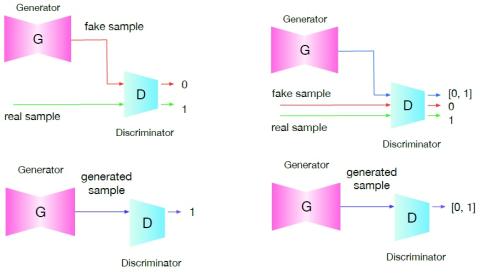
SoftGAN: Learning generative models efficiently with application to CycleGAN Voice Conversion
Voice conversion with deep neural networks has become extremely popular over the last few years with improvements over the past VC architectures. In particular, GAN architectures such as the cycleGAN and the VAEGAN have offered the possibility to learn voice conversion from non-parallel databases. However, GAN-based methods are highly unstable, requiring often a careful tuning of hyper-parameters, and can lead to poor voice identity conversion and substantially degraded converted speech signal. This paper discusses and tackles the stability issues of the GAN in the context of voice conversion....