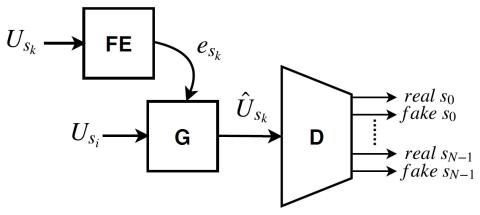
We present a Cycle-GAN based many-to-many voice conversion method that can convert between speakers that are not in the training set. This property is enabled through speaker embeddings generated by a neural network that is jointly trained with the Cycle-GAN. In contrast to prior work in this domain, our method enables conversion between an out-of-dataset speaker and a target speaker in either direction and does not require re-training. Out-of-dataset speaker conversion quality is evaluated using an independently trained speaker identification model, and shows good style conversion characteristics for previously unheard speakers. Subjective tests on human listeners show style conversion quality for in-dataset speakers is comparable to the state-of-the-art baseline model.
Discussion
In this paper, we describe a non-parallel, almost unsupervised, Cycle-GAN based voice conversion method that can perform conversions between speakers that the model was never trained on. This is enabled by a unique feature extractor block that produces speaker embeddings for new speakers. Subjective tests show that style conversion quality is comparable to the state of the art, which can only perform in-dataset conversions. Out-of-dataset conversion quality of the proposed model is compared to the in-dataset quality using a quantitative method based on an independently trained speaker identification model. Future work includes improving the naturalness of the converted speech by employing a vocoder, and improving out-of-dataset conversion quality by training on a larger set of speakers to enhance the generalization capability of the feature extractor.