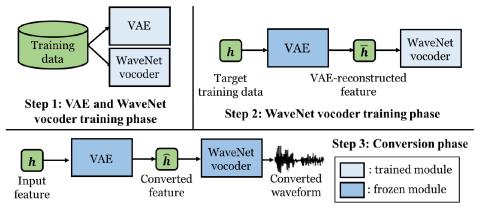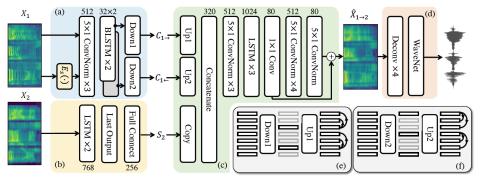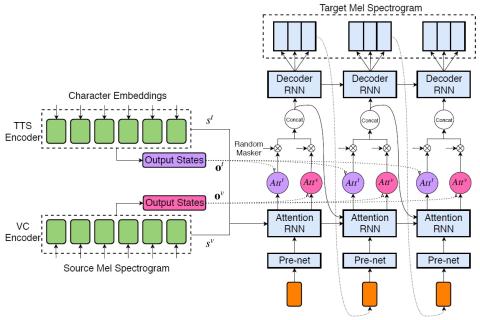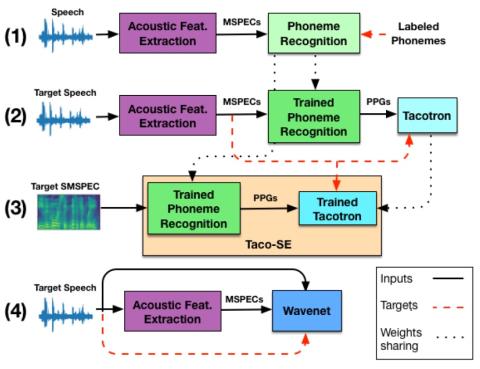
Taco-VC: A Single Speaker Tacotron based Voice Conversion with Limited Data
This paper introduces Taco-VC, a novel architecture for voice conversion (VC) based on the Tacotron synthesizer, which is a sequence-to-sequence with attention model. The training of multi-speaker voice conversion systems requires a large amount of resources, both in training and corpus size. Taco-VC is implemented using a single speaker Tacotron synthesizer based on Phonetic Posteriorgrams (PPGs) and a single speaker Wavenet vocoder conditioned on Mel Spectrograms. To enhance the converted speech quality, the outputs of the Tacotron are passed through a novel speech-enhancement network, which...