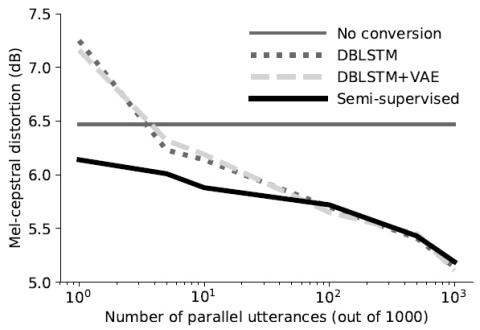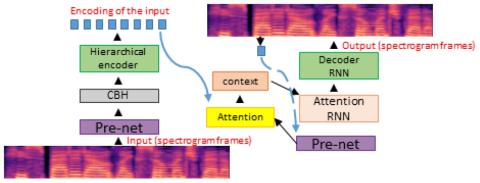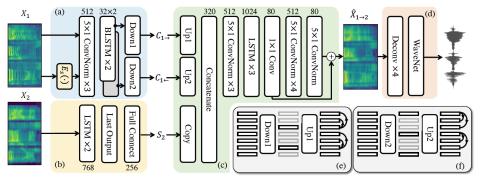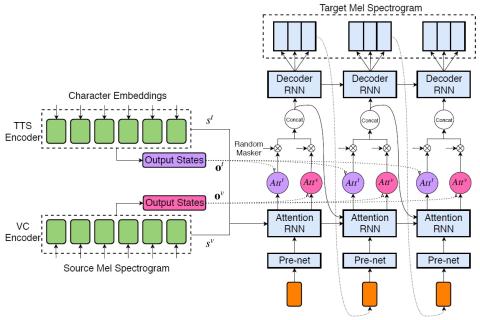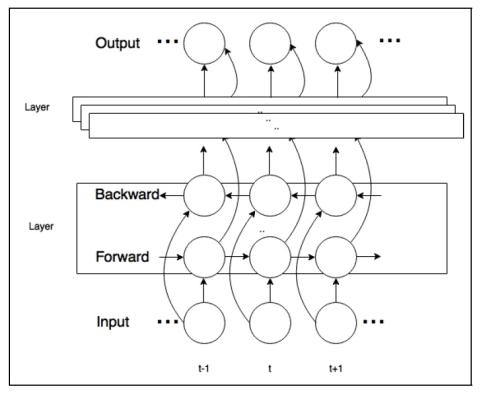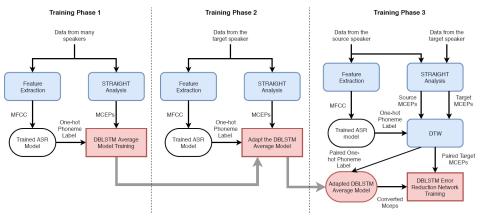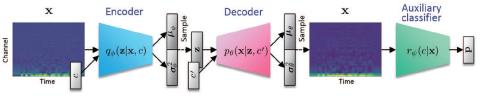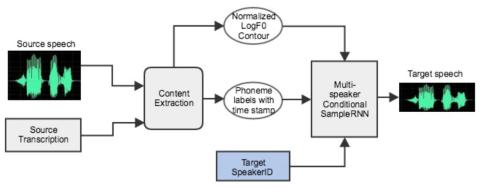
Модульная нейронная сеть с языковыми выходными слоями для межъязыкового преобразования голоса
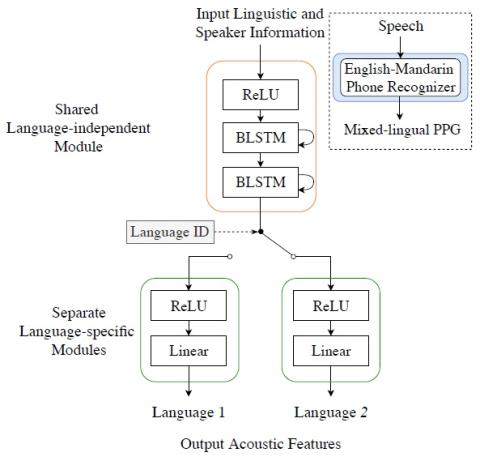
В этой статье представлена система межъязыкового преобразования голоса, использующая модульную нейронную сеть. Модульная нейронная сеть имеет общую структуру ввода, которая используется совместно для обоих языков, и два отдельных выходных модуля, по одному для каждого языка. Идея продиктована тем фактом, что фонетические системы языков схожи, поскольку у людей общая система воспроизведения голоса, но акустические способы передачи, такие как просодия и фонотаксика, сильно различаются от языка к языку. Модульная нейронная сеть обучена сопоставлять фонетическую апостериограмму (PPG) с акустически...