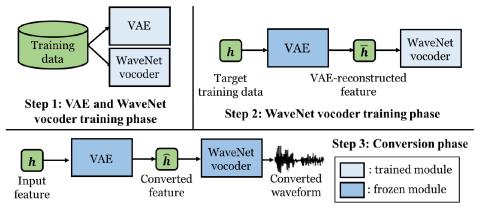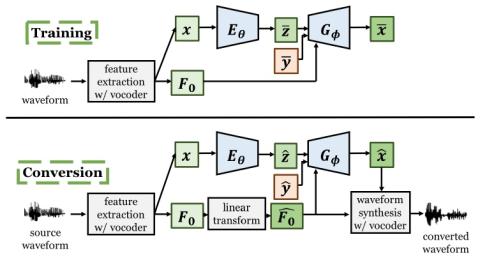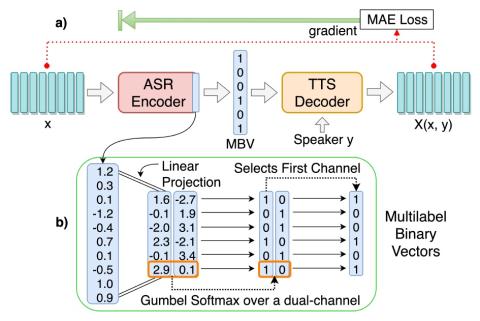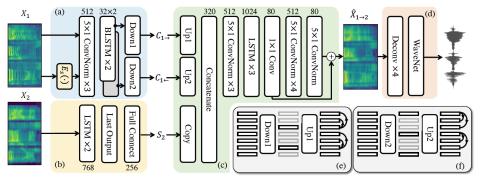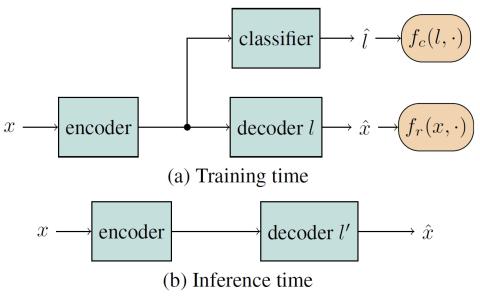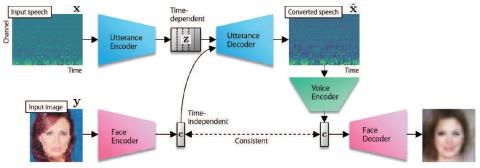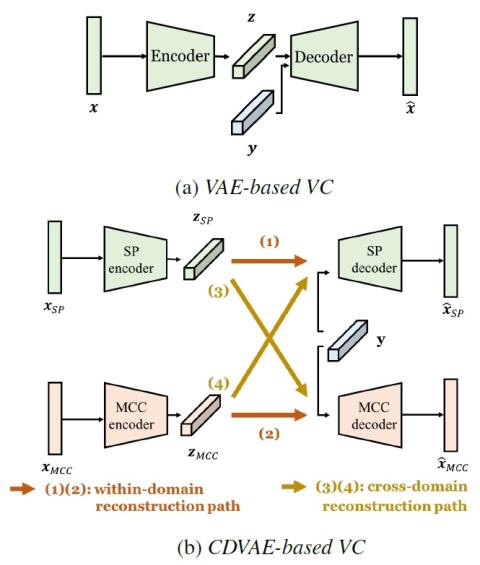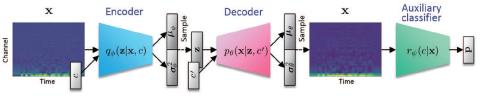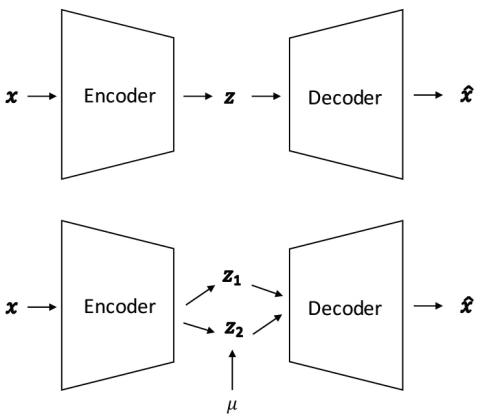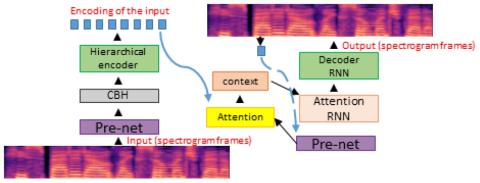
Иерархическое преобразование голоса из последовательности в последовательность с ограниченными данными
Мы представляем решение для преобразования голоса с использованием рекуррентного моделирования последовательности в последовательность для DNN. Наше решение использует последние достижения в области моделирования на основе внимания в области нейронного машинного перевода (NMT), преобразования текста в речь (TTS) и автоматического распознавания речи (ASR). Проблема заключается в параллельном преобразовании между голосами при наличии аудиопар. В нашей архитектуре seq2seq используется иерархический кодер для суммирования входных аудиокадров. Что касается декодера, мы используем архитектуру, основ...