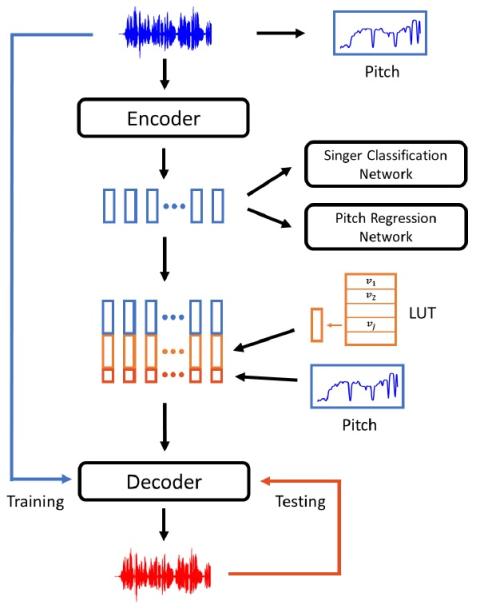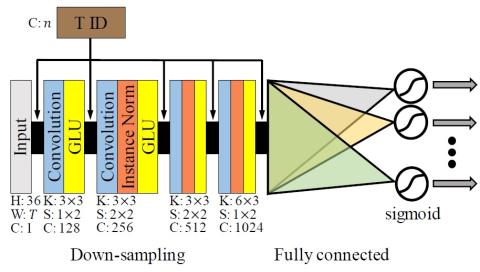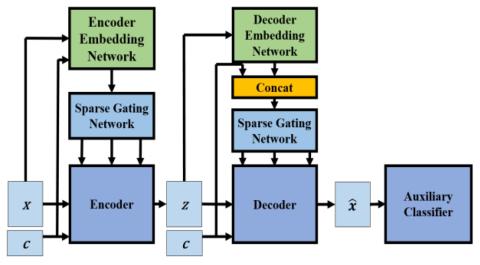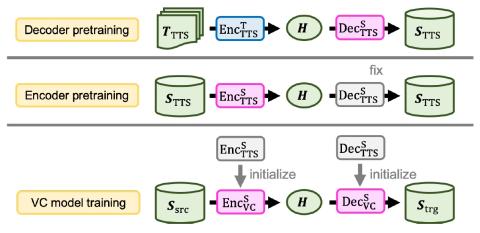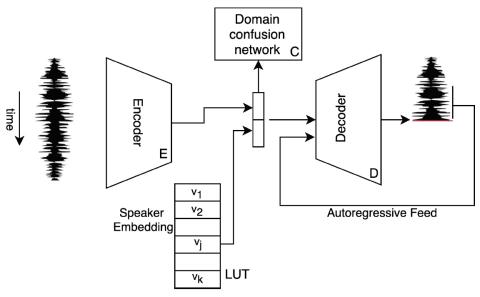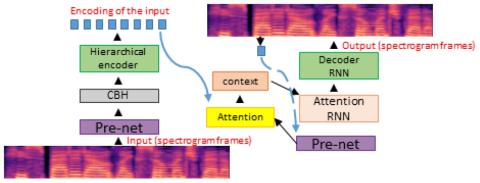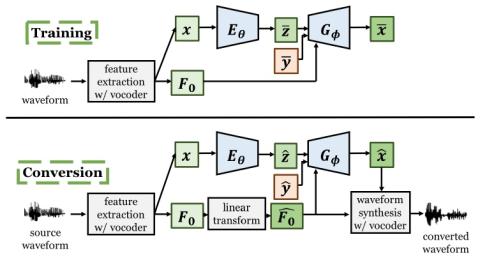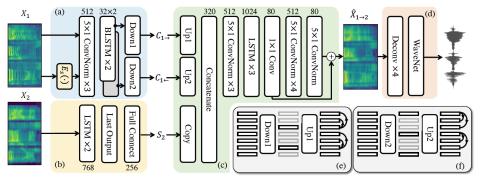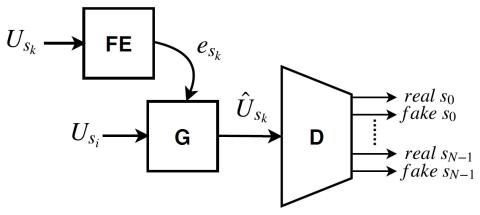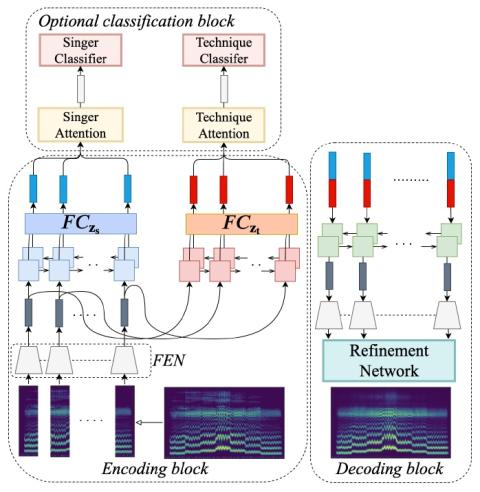
Преобразование певческого голоса с использованием разрозненных представлений о певце и вокальной технике с использованием вариационных автоэнкодеров
Мы предлагаем гибкую структуру, которая работает как с преобразованием голоса певца, так и с преобразованием вокальной техники певцов. Предлагаемая модель разработана на непараллельных корпусах, поддерживает преобразование "многие ко многим" и использует последние достижения вариационных автоэнкодеров. В нем используются отдельные кодеры для изучения скрытых представлений об индивидуальности певца и вокальной технике по отдельности, а для реконструкции используется совместный декодер. Преобразование осуществляется с помощью простой векторной арифметики в изученных скрытых пространствах. Как ко...