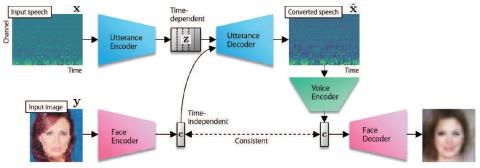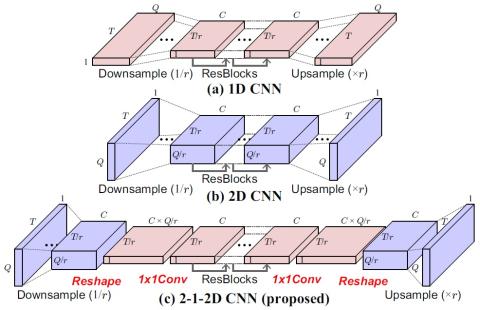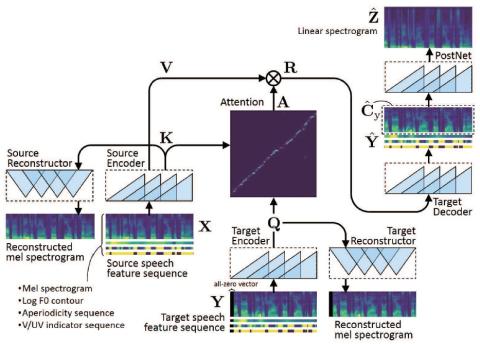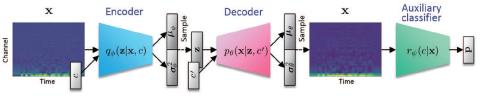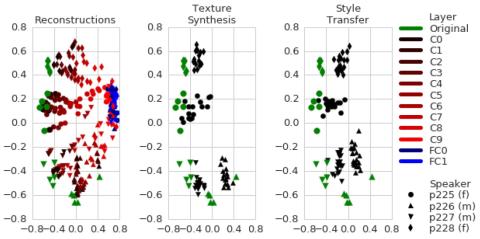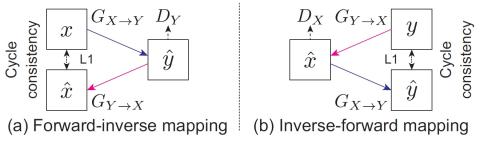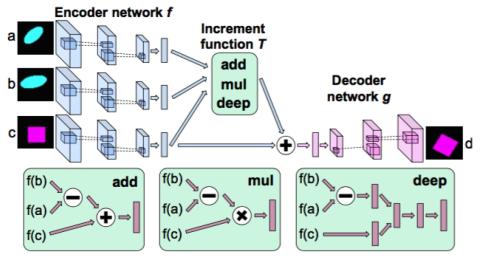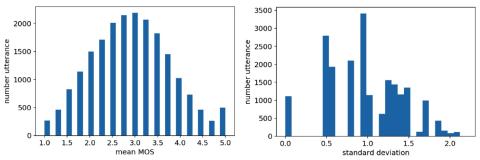
MOSNet: Объективная оценка преобразования голоса на основе глубокого обучения
Существующие объективные показатели оценки преобразования голоса не всегда коррелируют с восприятием человекоа. Поэтому обучение моделям преобразования голоса с использованием таких критериев не может эффективно улучшить естественность и сходство преобразованного голоса. В этой статье мы предлагаем модели оценки, основанные на глубоком обучении, для прогнозирования оценки человеком преобразованного голоса. Мы используем сверточную и рекуррентную модели нейронных сетей для построения прогноза среднего балла мнений (MOS), называемого MOSNet. Предложенные модели протестированы на результатах круп...