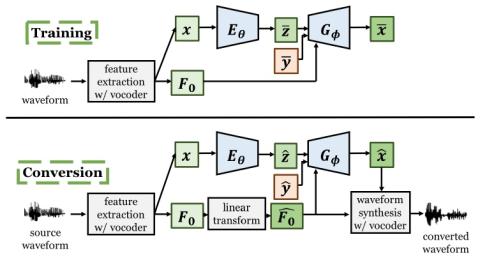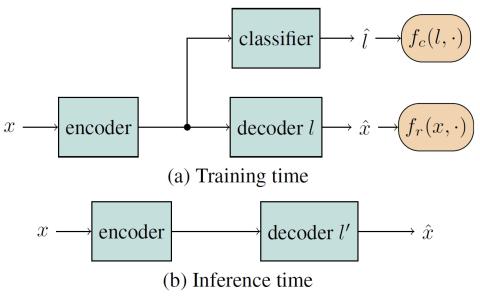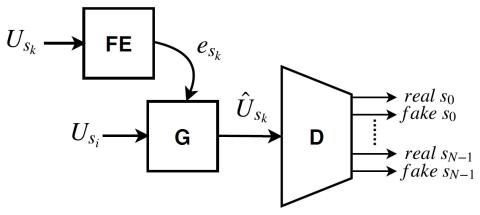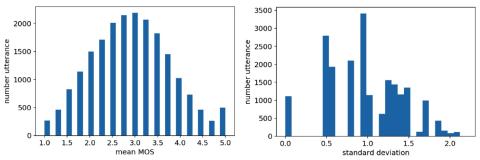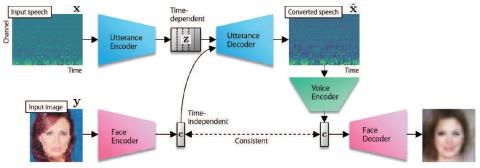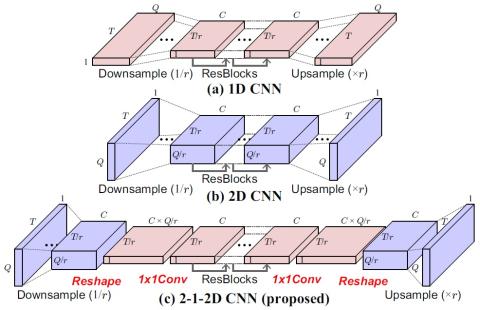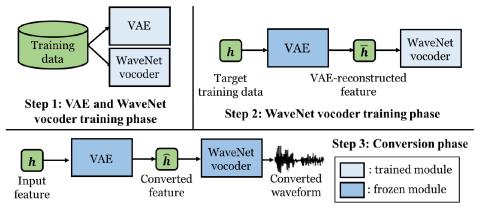
Усовершенствованный вокодер WaveNet для преобразования голоса на основе вариационного автоэнкодера
В этой статье представлена усовершенствованная система вокодеров WaveNet для преобразования голоса на основе вариационного автоэнкодера (VAE), которая уменьшает искажение качества, вызванное несоответствием между данными обучения и тестирования. Обычные вокодеры WaveNet обучаются с учетом естественных акустических характеристик, но зависят от преобразованных характеристик на этапе преобразования голоса, и такое несоответствие часто приводит к значительному ухудшению качества и сходства. В этой работе мы используем преимущества особой структуры VAE для усовершенствования вокодеров WaveNet с пом...