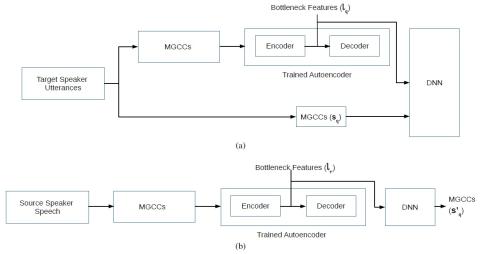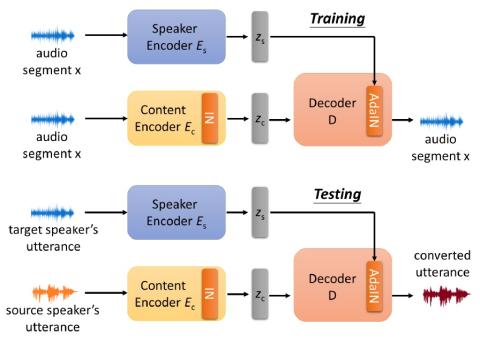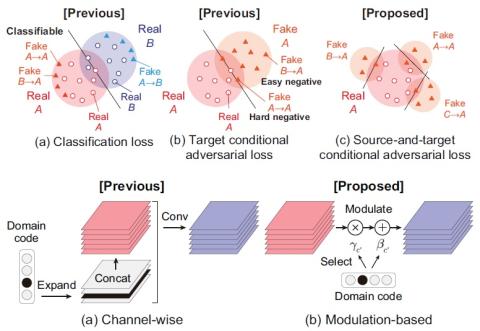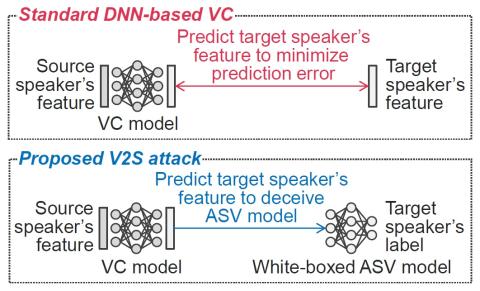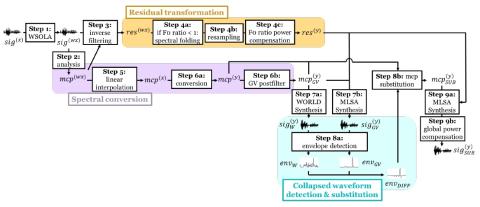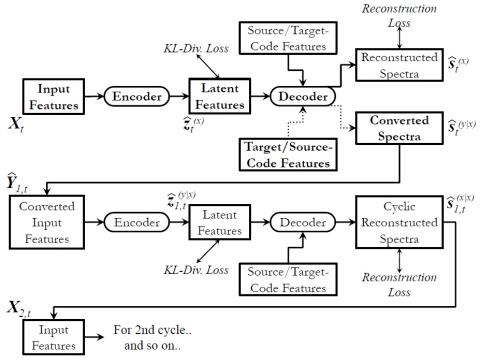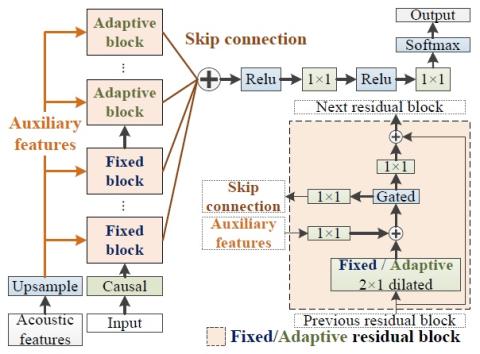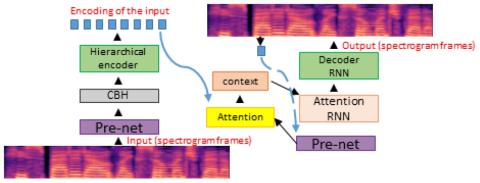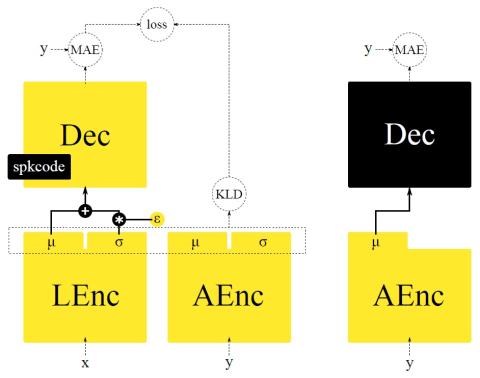
Самонастраивающееся непараллельное преобразование голоса из диктор-адаптивное преобразование текста в речь
Преобразование голоса и текста в речь - это две задачи, которые преследуют схожую цель: генерировать речь с помощью целевого голоса. Однако, как правило, они разрабатываются независимо друг от друга в рамках совершенно разных платформ. В этой статье мы предлагаем методологию начальной загрузки системы преобразования голоса из предварительно подготовленной модели преобразования текста в речь, адаптируемой к диктору, и объединяем методы, а также интерпретации этих двух задач. Более того, благодаря переносу большого объема данных на этап обучения модели преобразования текста в речь, наша система ...