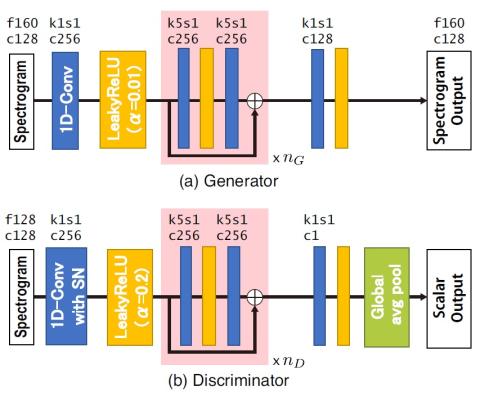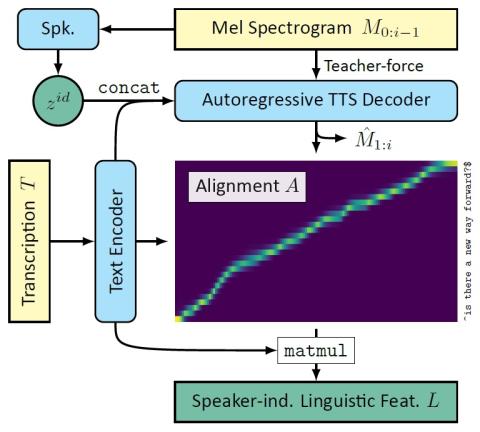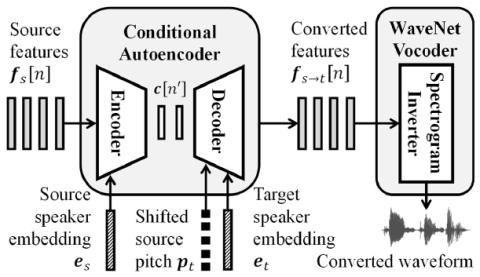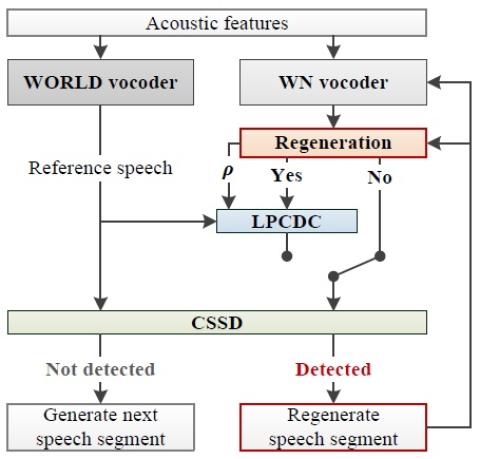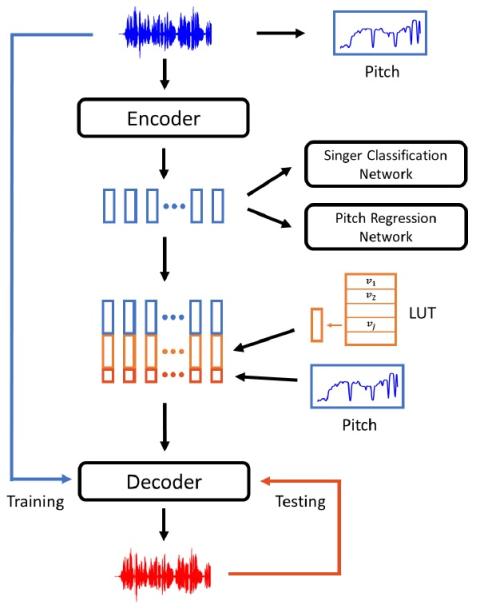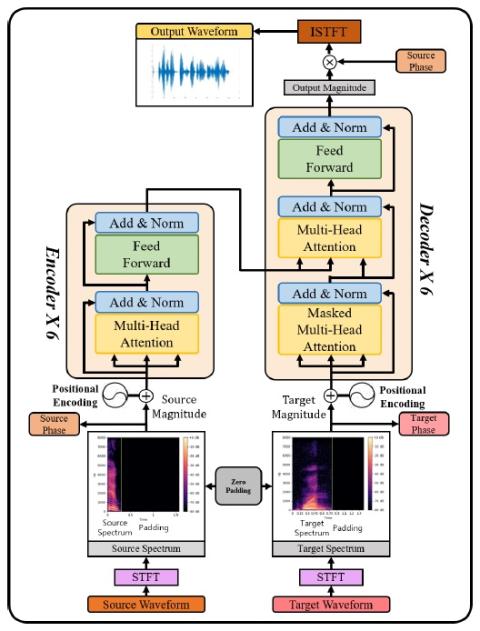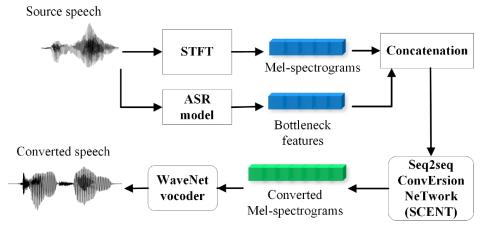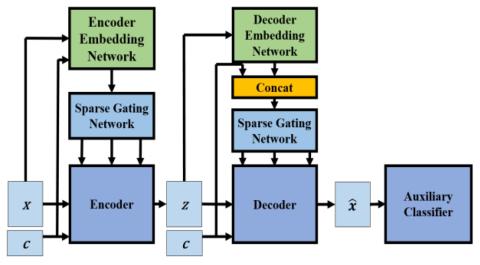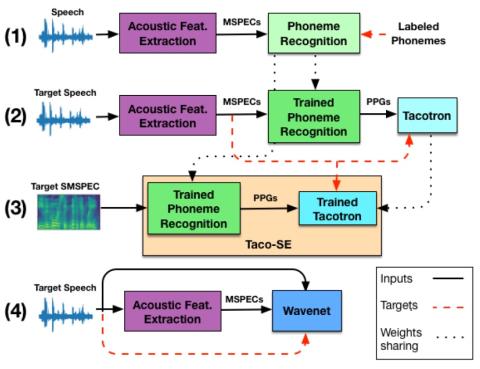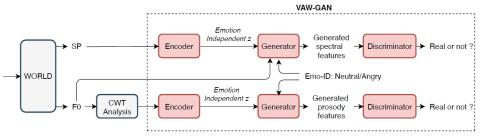
Преобразование чьей-либо эмоции: на пути к независимому от диктора эмоциональному преобразованию голоса
Эмоциональное преобразование голоса направлена на преобразование эмоции речи из одного состояния в другое при сохранении языкового содержания и идентичности говорящего. Предыдущие исследования по эмоциональному преобразованию голоса в основном проводились в предположении, что эмоции зависят от говорящего. Мы считаем, что эмоции выражаются универсально у всех говорящих, поэтому возможно независимое от говорящего отображение эмоциональных состояний речи. В этой статье мы предлагаем построить независимую от диктора структуру эмоционального преобразования голоса, которая может конвертировать любые...