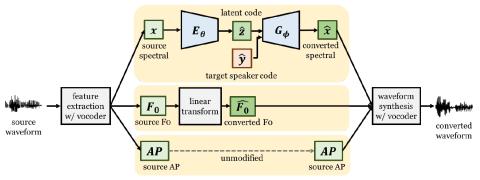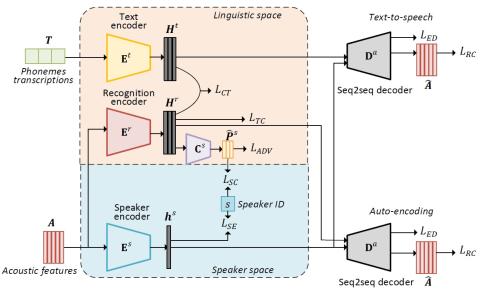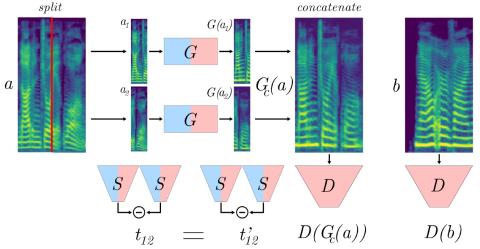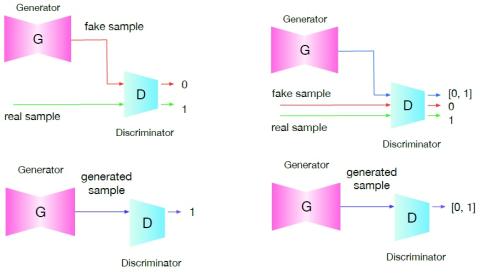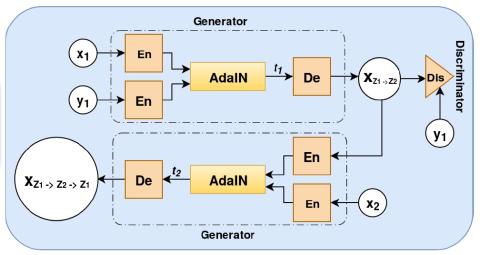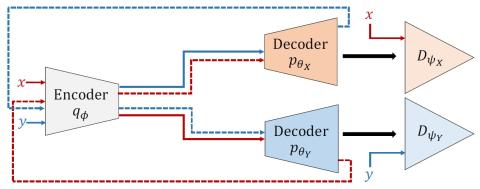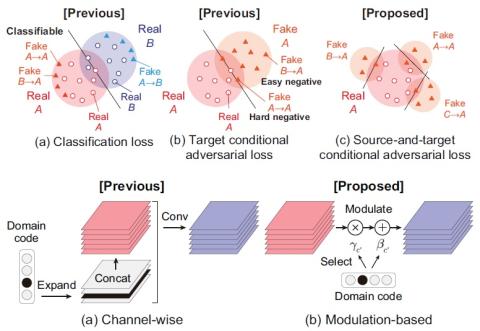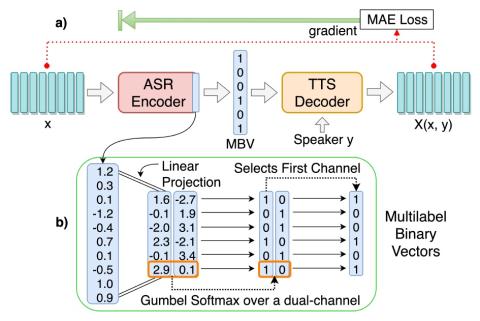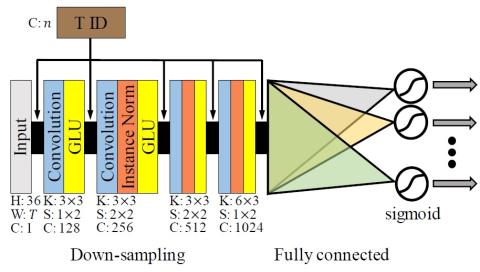
Преобразование голоса "Многие ко многим" с использованием состязательных сетей, согласованных по условному циклу
Преобразование голоса (VC) относится к преобразованию характеристик говорящего при произнесении без изменения его лингвистического содержания. Многие работы по преобразованию голоса требуют наличия данных для параллельного обучения, приобретение которых является очень дорогостоящим. Недавно для преобразования голоса была применена циклически согласованная состязательная сеть (CycleGAN), которая не требует параллельного обучения данных, что демонстрирует самую современную производительность. Однако преобразование голоса на основе CycleGAN может использоваться только для пары говорящих, т.е. пре...